
02
7 月
赛博达芬奇
- By IanGoo

大概在2022年底,AI画师这个概念突然被推上了风口浪尖。甚至还掀起了一股真人画师的抵制潮,一些美术社区如ArtStation也开始采取手段,要么拒绝AI画作,要么会打上特殊标签。
半年时间过去,画手们仍然在抵制,但是却有越来越多的玩家加入了AI绘图的圈子,随着算法和模型的精进,AI画出来的图也越来越像那么回事。
有人说,机器最难取代的职业就是艺术家和设计师这样的“创意”职业,但是现实情况,画师们创不创意另说,他们确实是快被AI给创死了。
设计师目前看来还算安全,但是作为职业搞事情的,我当然需要深入了解一下AI画图究竟是怎么一回事,除此之外,还会介绍一下其中的一些关键的概念,以及如何实操,最后,作为汽车设计部门,如何利用这一强大的工具——是的,AI再强大,目前它的定位仍然应当是“工具”。
(本文所有的配图,除图表外,均由Stable Diffusion生成,以示尊重)
Contents
机器会思考吗?
在开始介绍Stable Diffusion之前,我们需要回溯70余年,在那个计算机还在蹒跚学步的1950年代,计算机科学的上古先贤Alan Turin就提出了这个问题。
在达特茅斯会议之后,人工智能作为一个学科正式成立了。但是想要搞“人工智能”,是不是应该先弄明白啥是“智能”?最初,人工智能的科学家们的想法很单纯:智能是一种符号计算。因此,这一流派也被称为“符号学派”。符号学派的哲学由来已久,甚至可以一直追溯到笛卡尔。在符号学派看来,人类的智能是一种符号化的逻辑推理:我看到了一个红色的、大致呈圆形的东西,表皮光滑带着褐色的小点点,这些规则放到一起,所以我认为这东西是个“苹果”。
符号学派力图将所有的人类认知符号化,塞到一个逻辑计算系统当中,这种做法造就了最早的人工智能系统之一——LT(Logic Theorist,逻辑理论家)。LT在逻辑推演方面展现出了相当的能力。1910年,伯特兰·罗素和他的老师阿尔弗雷德·怀特海合著了一套书叫《数学原理》,但是这本书并不是一本单纯的“数学书”,而是一本哲学和逻辑学巨著。比如1+1,小学二年级的都知道等于2,但是在该书当中,作者先用两页纸定义了什么是“自然数1”,然后用十几页对自然数加法做了严谨的定义,最终得出结论:1+1=2(实在抱歉,只能说到这种程度,因为我……看不懂)。之所以突然拐这个弯,是因为LT很轻易地就证明了《数学原理》中的38个定理。
这样的逻辑推理能力很快让AI找到了一条工业应用的出路——知识工程和专家系统。在符号学派看来,企业当中的专业决策也是可以用符号来抽象的——XXX工艺牵涉到12345678条其他工艺,它们之间构成了87654321条工艺路径,分别的成本是多少,效益是多少,逻辑推断就完了嘛。在这样的思路的引领下,专家系统一时领AI风潮之先,风头无两。最高光的时刻是1980年卡耐基梅隆大学为DEC开发的一款名为XCON的专家系统,每年可以为DEC节约成本高达4000万美元。而在公众视野中,符号学派知名度最高的则是1997年IBM Deep Blue击败了国际象棋大师加里·卡斯帕罗夫。但是,在1997年的时间点上,符号学派已经不行了。
符号学派的哲学非常优美,它试图建立一套牛顿运动定律一般的规则,小到孩子玩的玻璃球,大到宇宙间的天体,都按照这一套规则来规规矩矩地运行。但是,人……好像不那么讲“规则”。就像某蔡姓明星,符号思维会给出他的基础信息、有哪些作品,但是在某些人类群体当中,他们的第一反应是白色背带、中分头、某家禽和篮球这样“毫 不 相 关”的内容(你干嘛~~哎唷)。
所以,符号在人类这里,似乎是一种抽象,一种交流的手段。真正底层的“思维”,是极难进行符号化表达的。所以说书的形容美男或者美女,经常用四个字——“一想之美”,这种评判基本无法用“眼距多少、鼻梁高度多少、耳朵多大”这种符号化的手段来描述。那么,如何用机器来模拟这样疯狂的“潜意识”思维呢?
回到达特茅斯会议。相较于已经能够端出LT这样能用的成品的符号学派,另一个学派颇有些空手瞎BB的特质。他们提出,希望用计算机来模拟人类神经元处理电信号的模式来模拟“思考”的过程,这个学派被称为“连接学派”。但是连接学派长期以来都是处在空手瞎BB的状态,迟迟拿不出任何工业应用,一直到1987年反向传播法的提出,人们才意识到可以用“训练”的方法来调教人工神经网络,此后,连接学派一飞冲天,而符号学派由于各种各样的困难停滞不前。时至今日,连接学派是人工智能领域实质上的显学,我们今天几乎所有的人工智能应用,都是基于人工神经网络的。
基本原理
我们今天提起“AI”,对于非程序员来说,总觉得非常神秘且牛批。但是实际上,这玩意儿玩起来并不复杂,下面我也会介绍如何部署。
而它的基本原理,我们需要一层层地来介绍。
首先,是最基础的概念:人工神经网络(Artificial Neural Networks,ANN)。ANN也是目前几乎所有AI设计的基础。
ANN的基本概念
如前所述,连接学派的计算机科学家们在电脑上复现了“神经元”这一概念。现在,我有一个参数,通过某种加权,输出了另一个参数。输入的参数就可以理解为一个人造神经元,输出的参数是另一个人造神经元,但是和输入的神经元不在一层,中间的加权参数就可以理解为神经递质传递电信号的过程。需要说明,这些参数在现实当中普遍是多维数组,而不是一般理解中的一个数字,在AI领域将其称为“张量”(Tensor),不过需要注意,这个“张量”和数学领域的“张量”不是一个意思。为什么要用多维数组也很好理解,以机器视觉为例,机器的传感器传回的一张图片需要拆成像素点,每个像素点就有位置和颜色两个参数,位置需要用一个1×2矩阵来表示(X,Y),颜色则需要1×3矩阵(R,G,B),我们看到的每一张图片,都是一个庞大的RGB矩阵构成的大矩阵。这些多维数组就构成了神经网络的一个神经元(参数),如果有若干个输入和若干个输出,它们之间就会构成一个网状的结构:
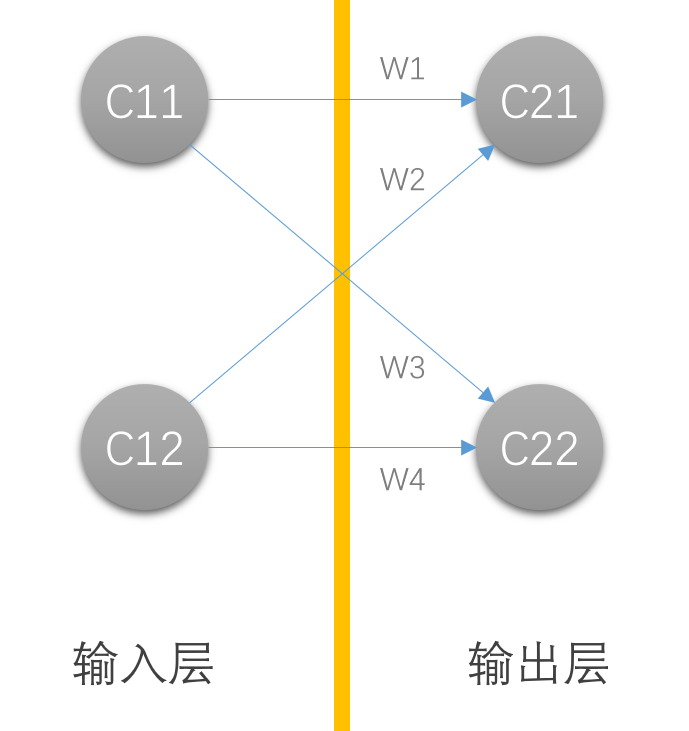
但是在实际的操作当中,我们可能还需要在前一层加入一些别的东西,比如额外的恒定参数(称为截距),还可以加入一个激活函数,只有满足激活函数的条件,才会连接特定的神经元,这被称为阈值,同时,为了更为强大的功能,我们还可以加入更多的层数,除了最开头的输入层和最后的输出层,还需要在中间加入若干隐含层,这就为神经网络赋予了“深度”。
这样的ANN的完全体,就是深度神经网络(Depth Neural Networks,DNN)。
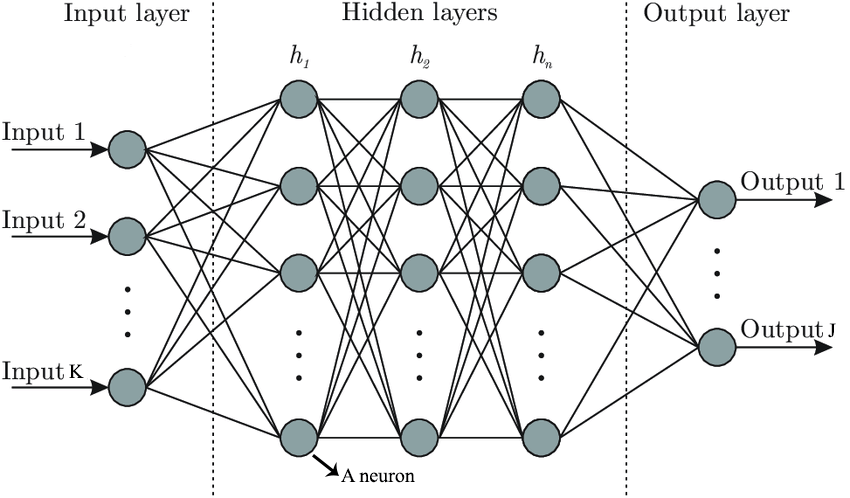
一个DNN可以很复杂,类似GLM或者Stable Diffusion那样的模型当然会非常复杂,但是也可以很简单。比如,可以用三层(一个隐含层)、两个输入、一个输出、三个隐含层神经元搭建一个非常简单的神经网络,通过训练让它实现100以内的加法。
这时候略有码代码基础的设计师会震惊了,明明一行print(a + b)能搞定的事情为啥搞这么复杂?
其实很简单:泛用性。DNN具备学习的能力,只要告诉它“正确”的结果是什么,它会通过调节参数来将自己“变成”能够输出正确结果的样子。上面的代码中包含了10000次训练,这一万次训练告诉DNN:我给你一个1、一个2,你应该输出3,给你一个4、一个5,你应该输出9,如此不断训练,它就会“学会”做加法。
那么这时候突然改了需求,我要让这个DNN做乘法怎么办?那很简单,这个三层DNN的核心部分根本不用改,我只要修改训练的部分,告诉DNN:给你一个2、一个3,应该输出6;给你一个5、一个7,应该输出35,如此往复,这个DNN又会变成一个“会做乘法”的DNN。而在实际的应用当中,训练与核心DNN往往是解耦的,会写在不同的模块里,这就使得DNN变成了一个百变怪:工程师无需修改核心代码,只要通过训练,就可以让DNN改变功能。也许训练一个DNN做加法或者做乘法很蠢,因为在这种很简单的功能当中,训练的成本比改一行代码要高,但是如果功能很复杂,甚至完全难以用人工方式来量化呢?
比如,识别图像?
深度神经网络与深度学习
如果,我们要用DNN来实现某个功能,比如,识别一张图片。那就需要将一个输入矩阵通过一系列参数进行转化,将其提取为特定的特征,若是符合某个特定描述的特征,就将这个描述输出出来。
那么问题来了,这里面的转换参数怎么写?
很显然,如果要手写的话,这是一个不可能完成的任务。所以,手写个辣子,得用魔法打败魔法——就是上面提到过的“训练”。

在我们很小的时候,看到大街上有一个个飞驰而过的大铁盒子,听到它们发出或大或小的噪音,父母会告诉我们:这些东西叫做“汽车”。我们用自己的眼睛看它们在不同速度、不同天气下的样子,渐渐地将这个特定形状与行为方式的东西与“汽车”这个描述产生了关联。甚至某些特定的特征印象更为深入,如人的形状、人脸的形状等,这些甚至已经刻到了DNA里,某种程度上达到了“硬件加速”的效果:还没有意识到的时候,潜意识就已经作出了反应。
OK,这是一个结果,我们有结果就行了,至于我们大脑里的神经元是怎么裁剪才能让我们人类形成概念性的记忆并且对特定的物品与概念之间产生关联……Hmm,不在乎,有结果就行。
这种过程就是训练。
DNN一样可以训练。我们只需要告诉DNN一个输入对应着什么输出,让它自己去修正内部的各个参数,通过拟合来实现我们告诉它的“正确结果”,当训练量达到一定程度之后,一个DNN就会变成一个程序员自己都不知道里面是什么鬼参数集,但是它就是能用的玩意儿。
这个过程,就是“深度学习”。
除了DNN,还有一些其他的“神经网络”的概念,比如用于图像识别的卷积神经网络(Convolutional Neural Networks,CNN),中间加入了若干层使用3×3矩阵(称为卷积核)处理的隐含层,通过卷积核的处理可以较为方便地提取图像的某些特征。按你胃,这些都是某种形式的神经网络,都需要训练并形成特定的模型才能正常使用。
是不是听起来极为不靠谱?
事实上,人工智能自诞生以来,就存在两种根本路线上的讨论:符号主义和连接主义。符号主义主张用公理、符号和逻辑体系搭建一套严密的人工智能系统;而连接主义就是模仿人类的神经元,ANN就是连接主义的实现。
目前看来,连接主义取得了全面胜利——智能并不是靠一堆准确的公式来计算的,而是靠巨量的ANN神经元来“拟合”的。每一个神经元都是一组多维数组或者说“张量”,这些运算并不复杂——事实上手算都是可以的。但是随意一个模型可能都有数百万个这样的神经元需要同时计算。这是一个很典型的难度不大但是规模巨大的运算模型。什么东西擅长做这样的计算呢?
显卡。
事实上,多维数组的简单计算和三角面的着色显示有很多相通之处,随着GPU的性能的发展和专门用GPU来进行通用计算的技术的发展,现在的多数人工智能模型都是基于GPU来进行的了。相比之下,一台电脑的“中枢”,CPU,反而并不擅长做这类事情。CPU更擅长较为复杂的少量计算,GPU更擅长大量的简单运算。这也就是为什么AI的运算总是离不开显卡。
较早布局的是NVIDIA,目前NVIDIA的CUDA已经成为了AI计算的事实基础,所以,想要玩AI,包括本次要介绍的Stable Diffusion,一块高性能NVIDIA显卡总归是跑不掉的。
Stable Diffusion的基本概念
那么,如果我们不是从图片中提取特征让一个AI告诉我们图里是什么东西,而是反过来,我告诉AI一个东西,让它来生成图片,这样行不行?
当然没问题。神经网络能够实现的东西远远超过我们的想象。这就是我们今天主要要介绍的东西——Stable Diffusion干的事。Stable Diffusion可以做的事情有很多,最基本的是输入一串文字来描述你想要什么东西,让SD去画;也可以输入一张图片,选择性地加入一些文字描述,让它去二次创作,包括:去掉画面里的某个物品、放大画面、修改画面风格等等。
通过简单的文字和/或图像输入来生成复杂的高精度图片的尝试其实早已有之。在Stable Diffusion之前,这种功能的主要实现方式是生成对抗网络(Generative Adversarial Networks,GAN)。早在几年前,NVIDIA就发布了一个Demo程序,输入一个幼儿园涂鸦级别的简笔画,它能生成非常高精度的图片。
这个Demo软件叫NVIDIA Canvas,可以在NVIDIA的网站上免费下载:https://www.nvidia.com/en-us/studio/canvas/。
还有一些很奇怪的网站,什么thispersondoesnotexist、thesecatsdonotexist、thiswaifudoesnotexist之类的,都是使用GAN来生成的各种世界上不存在的人的脸、猫猫和二次元纸片人老婆。
GAN之所以叫“对抗”网络,是因为它包含两个主要的DNN,一个是生成器,会根据输入参数生成一系列噪音信号,另一个是评价器,会根据参数对生成器生成的东西进行评估,像极了设计师肝图,一群大佬评审,最后选出过关的,Bingo!而为了让最后过关的方案水平够高,首先设计师水平得够高,这就得训练,这还没完,评审的大佬也不能太菜,得吃过见过,知道什么样的图是好图,这也得训练,所以GAN的训练是分两部分进行的,一部分是训练生成器,另一部分是训练评价器,成本相对较高。
但是,随着扩散模型(Diffusion Model,DM)的提出,GAN似乎马上开始降温了。Stable Diffusion能够将GAN的风头抢掉,原因主要有二:
第一、它完全开源且免费。所以尽管有同样使用DM的DALL·E和MidJourney珠玉在前,Stable Diffusion还是普及度更高。
第二、它支持本地部署,而且对计算机的性能要求不高——当然,只是相对的“不高”,OpenAI有大把的计算卡和超算集群供DALL·E使用,我们自己的电脑相对来说当然寒酸很多,不过无论如何,Stable Diffusion对计算机的性能要求还是有一些门槛的。
DM对硬件性能的低要求,其一是训练难度要比GAN低得多,它不需要训练评价器,只需要训练生成器就能生成高水平的图片。这究竟是怎么做到的?
那就得首先弄明白一个关键概念:“扩散”究竟是啥?
我们试想,用水溶性彩铅画一张图,然后反手扔进水里。彩铅会溶化、扩散,最后整张图化成了一滩不可名状的颜色,这个过程就是“正向扩散”。
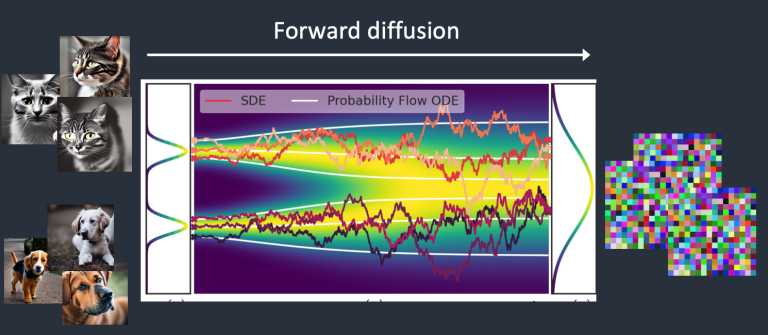
正向扩散之后,图像会变成一滩噪音,喵星人和汪星人不辨你我。
既然有正向扩散,那么我们能不能将这个过程逆转过来,形成一个“反向扩散”的过程呢?
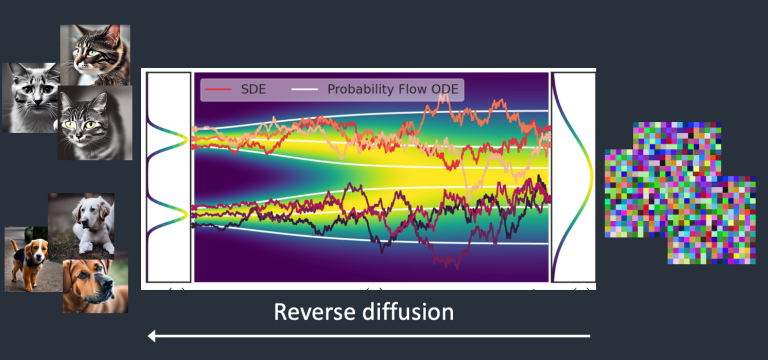
理论上可以。我们只需要知道正向扩散的每一个时刻,像素点是如何漂移、变色的就OK了。听起来很简单是吧?来,这位同志,听说过热力学第二定律的铁拳吗?
确实,如果是在现实世界当中,我们想要将一张扔进水里的水溶彩铅手绘猫猫头还原出来,会遭到天国的拉普拉斯妖[1]的无情嘲笑,但是当我们身处电脑里的赛博空间的时候,情况就完全不一样了——因为我们可以拥有自己的赛博拉普拉斯妖,还是由我们的老朋友——DNN来扮演。
首先,我们输入一张猫猫头,然后让DNN来一步步添加噪音,直到整个画面都被噪音淹没。
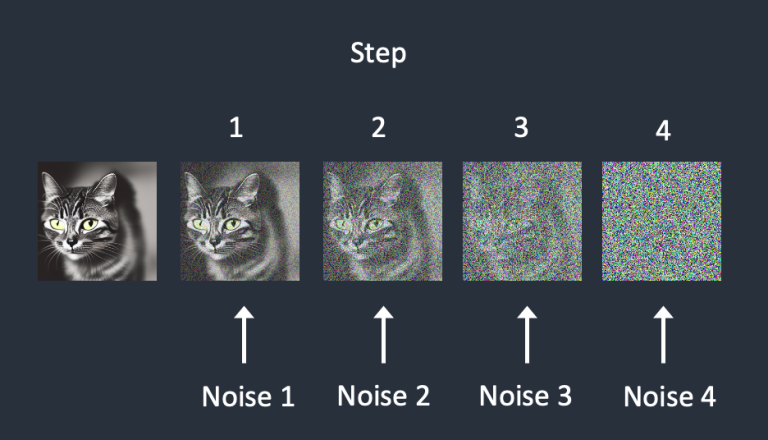
Hmm,我们每一步添加噪音都是由DNN来完成的,而DNN是我们自己养大(训练)的,它是可控的,每一步添加噪音对信号(图片)做出了什么修改也都记录在案,那么这就意味着,这个过程是可逆的:

那,我现在告诉DNN,你刚刚这一系列猛如虎的操作,你的内部的参数集就是对应着生成猫猫头的这一套模型,记好了!Bingo,训练完成。下次让DNN画一张猫猫头,它就会在生成噪音的基础上搬出这套参数集,一步步将噪音变成猫猫头,由于初始噪音有些许变化,最后生成的猫猫头也会有轻微的不同,按你胃,对于人类来说大差不差,反正人脑子的精度那是糟糕得可以,认识这是个猫猫头就算绘画成功了。而如果我们当初是拿小狗训练的这个DNN,那么同样的一摊噪音,它的反向扩散就会生成一张狗头的图。因为这两个DNN内部的参数集是不一样的。
当然,这是纯理论上的“训练”,现实中的训练起步就得上百张图片,对图片的描述也更加多元和丰富,这样才能训练出一套能用的模型出来。
所以,如果我们看DM的画图方式,就会发现它竟然和人类绘画颇有些相似,起手是一团团模糊的色块,这些色块是通过种子(Seed)随机生成的噪音,然后再进行细节的添加(反向扩散),这个添加细节的过程从信号处理的视角看就是“降噪”,所以DM模型生成图片的方式是生成噪音→降噪细化,如此反复若干次,最终完成。以这张图为例:

上图的prompt很简单:
a red ferrari, parked on grassland这是在画到10%的时候打断施法得到的全是噪音的图,但是从这张中间状态里已经可以看到AI已经知道这张图的主题是背景里是草地,主体是一辆红色的Ferrari跑车,于是初步喷出来的噪音也是绿底红色主体的风格。
VAE
SD对硬件的低要求的第二个重要原因是变分自动编码器(Variantional Autoencoder,VAE)。上面介绍了正反向扩散的概念,那么,正反向扩散操作的对象是什么?这个问题就比较有趣了。Google Imagen和OpenAI 的DALL·E是直接操作像素。这很合理,毕竟Google和OpenAI那叫一个财大气粗,随便掏出一个计算中心就能碾压一个小区的所有PC算力之和,但是SD那是可以本地部署、跑在一个算力非常卑微的个人计算机上面的。以像素为操作单位就太过分了,因此,SD使用了VAE来对图像的信息进行压缩,以SD1.5的VAE处理的默认单位:一张RGB色彩空间、512×512px的无压缩位图为例,它的像素空间是一个3×512×512的张量(512×512个像素,每个像素分别有R、G、B三个值),但是经过VAE的压缩,最终可以得到一个4×64×64的张量(称为潜在空间),数据量为像素空间的1/48,上述的正反向扩散都是在这个潜在空间上操作的,而非原始的像素空间。操作完成之后再将其进行解码,最终得到想要的图片。
这也解释了一个挺有趣的事实:如果你已经实际上手玩过一些AI画图的话,就会发现一个Bug:选择了高分辨率出图(比如横向分辨率1024),明明在关键词里已经写明了只要一个人物,但是出来的图里愣是有两个人,这个问题在笔者画题图的赛博达芬奇头像的时候造成了很大的困扰,后来查到VAE的工作原理才惊觉问题所在:由于SD是以一个4×64×64的潜在空间为单位的,对应着512×512的像素空间,如果将横向分辨率设定过高,那么SD就需要调取两个甚至更多的潜在空间来操作,一个潜在空间里塞一个人,最后画出来的就是好几个人,所以题图是使用512×512像素进行绘制,然后再用SD的升采样拉伸到高分辨率的。这是个小小的诀窍。
CLIP
OK,我们已经基本搞清楚了如何从一摊噪音通过反向扩散的方法来画图,那么在整个流程的最前端——输入文字,这些文字是如何让SD理解的呢?
SD自带了一个组件,叫对比语言-图像预训练(Contrastive Language-Image Pre-training,CLIP)。这个组件是由OpenAI开发的,并且已经开源(源码地址)。
当我们输入一串文字的时候,CLIP首先会对文本进行“标记化”操作(Tokenization)。标记化会将单词转化为令牌(Token),也就是一串数字。需要说明的是,CLIP的操作看起来很笨:它只能理解训练过程中它见过的单词,其他单词它会略过,所以在写文字输入的时候,我们更倾向于使用一些简短、清晰的描述。另外,需要特别说明的是,空格在CLIP当中也是被作为一个字符来处理的。所以,如果我们画图使用的模型在训练的过程中提到了“hair”和“cut”,那么它看到“haircut”这个字的时候,会一脸懵逼地将它拆成“hair”和“cut”两个字,各自标记化,形成两个Token。而如果模型里带有“alarm clock”,那么看到“alarm clock”也只会生成一个Token。
SD的Token数量限制在75个,所以最多可以输入75条提示。
嵌入
Token随后会被用于生成一个嵌入向量(Embedding Vector)。
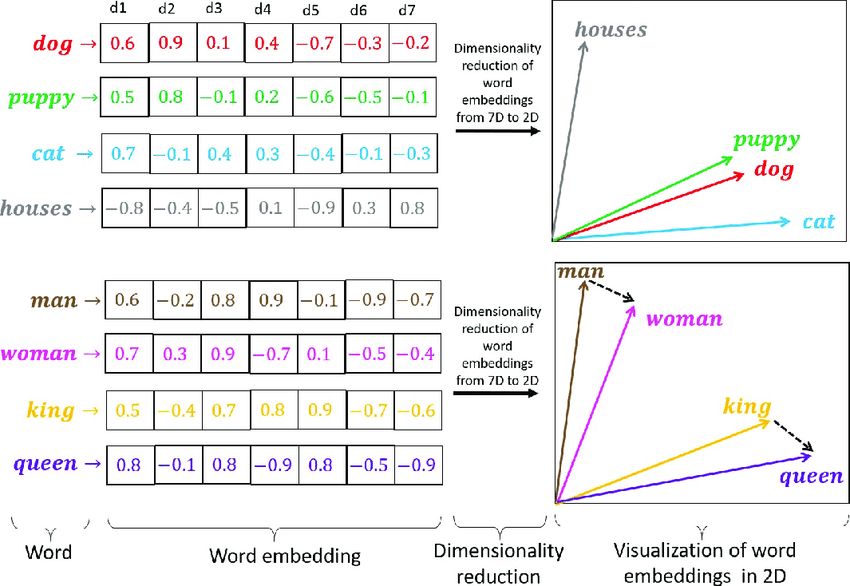
嵌入向量从某种程度上可以表征一个描述在语义上的相似性。如puppy、dog、cat三个字,puppy和dog之间的相似性就比dog和cat之间更高,这和人类理解语义的含义是一致的。为了实现嵌入向量之间的互相关联,SD引入了一个叫U-Net噪音预测器(Noise Predictor)的组件,通过交叉注意力机制(Cross-Attention)对提示词进行修整,如“a female with red dress, sitting on an armchair”,Cross-Attention机制会将“red”和“dress”关联起来,而不会跨老远将red和armchair关联起来。
在这个过程中,有两个我们未来会用到的概念需要提一下,一个是超网络模型(Hypernetwork),它可以再这个过程中通过劫持Cross-Attention模块来修改生成的图像风格;另一个是低秩适应模型(Low-Rank Adaptation,LoRA),它可以通过微调Cross-Attention的权重来实现微调进而影响出图的风格。
除了上述的模型,SD还可以根据图像、ControlNet来作为输出的参考。图像输入可以在SD的图转图功能中实现,而ControlNet则是通过类似3D角色建模中骨骼绑定的方式来描述角色的姿势,从而实现对画面内容的精确控制。
生成与输出
来自用户的输入准备完毕,SD就可以生成图片的工作了。
首先,SD会在潜空间当中生成噪音。但是众所周知,计算机其实不会生成真正的随机数,因此SD是以一个被称为“种子”(Seed)的数字来生成伪随机噪音的。当然,这个Seed本身也可以是一个伪随机数。
初步的、布满噪音的图像生成之后,就是不断地重复添加噪声、降噪这两步动作,具体完成多少步可以由用户来控制,默认的是20次,从噪音反向扩散的依据,就是上面所说的文字输入生成的嵌入向量、图转图流程中输入图像通过VAE转入潜空间的张量、通过姿态控制输入的参数等等,完成规定次数的采样之后,就会得到最终的潜空间,然后再由VAE进行解码,将潜在空间重新映射为像素空间,得到一张图片。
实际操作与重要概念
关于原理也就不多说废话了,毕竟我自己也不是很懂——手写三个人工神经元就烧掉了我三千个天然神经元。关键是,作为设计师,如何去用这个东西?
第一步,当然是部署。两种方式:在线服务和本地部署。
在线服务
很简单,直接践行SaaS的原则,找一个在线服务。类似的在线服务有很多,如Playground AI、Midjourney(部署于Discord)、DALL·E(OpenAI的服务)等,其中不少服务是要付费的。同时,由于是在线服务,其中不少一些服务还需要考虑科学上网的问题(如Discord和OpenAI)。虽然Stable Diffusion本体是免费的,但是如果想要使用一些在线的生成服务的话,某些时候是需要付费的,毕竟人家部署服务器和GPU资源那是要实打实花钱的。
这里是一些可以免费使用的Stable Diffusion的在线部署,可以在入门的时候简单了解一下如何使用:
- Huggingface Stable Diffusion 1.5 Demo Huggingface堪称机器学习领域的GitHub,在里面可以找到超过10万个预训练模型、超过1万个Data Sets,上面这个链接是Huggingface的SD 1.5 Demo页面。
- Mage.Space
- Playground AI
- Dezgo
- Histre Social Generative AI 比较老,只能支持Stable Diffusion 1.4。
- Stable Horde 大概是免费SD在线实现中最强大的一个,算力来自爱好者用自己的设备组成的运算网络,支持SD的大多数功能,但是由于算力完全依赖用爱发电,所以提交后需要等待很长时间才能看到结果。不过这共产主义精神可太赞了。
- Craiyon 它不是SD模型,而是一个精简版的DALL·E。
某些网站可能需要科学上网。
老是想办法在网上白嫖不太好,更关键的是,涉密的东西是不能随便往网上传的。所以,如果有必要的话还是需要在本地的电脑上部署一套。
本地部署
在本地部署之前,需要先确认一下自己的电脑能不能支持:
- 如前所述,SD生成图像和训练模型需要消耗大量的并行算力,目前在民用计算机上这样的算力的最佳来源就是显卡,而由于目前多数显卡计算模型都是基于CUDA的,所以只有NVIDIA的显卡能够比较好地支持。一块4G显存以上的NVIDIA中高端显卡是刚需。想要跑得比较舒服,8GB的显存是打底,至于最高多少——没有上限。24GB的RTX 3090也被我拉爆过。
- 将显卡驱动程序更新到最新版本。由于老的Windows 7已经不再支持新版显卡驱动,所以隐含的要求是得用Windows 10或者Windows 11操作系统。
- 大内存,至少16GB起步。
Stable Diffusion是一个基于Python的应用,并且所有的组件都在GitHub上开源了,所以在本地部署只需要安装好Python解释环境和Git就可以作为基础了(下载地址:Python、Git)。需要说明,Python的更新速度非常快,SD指定的Python版本目前还是3.10.7,下载指定的版本就可以。当然,有折腾Python基础的也可以直接用Embeddable+手动添加环境变量的方式来部署,能用就行。
SD只是一个核心程序,还需要一个组件来和它交互,目前比较流行的是Automatic1111开发的Stable Diffusion WebUI,它会在本地运行一个小型http服务器,让用户通过浏览器和SD交互。通过下面的命令在Windows上部署好WebUI就可以了:
cd %userprofile%
git clone <https://github.com/AUTOMATIC1111/stable-diffusion-webui.git>就这么简单。这里的%userprofile%指的就是用户目录,比如你的用户名叫“foobar”,那么用户目录在Windows里默认的位置就是C:\\users\\foobar。
部署完成后,可以下载模型,放到%userprofile%\\stable-diffusion-webui\\models下面,准备完成后,双击stable-diffusion-webui\\webui-user.bat运行,在等待一段时间后,直到黑框白字提示:
Running on local URL: http://127.0.0.1:7860
此时就代表SD运行完成,打开浏览器,输入http://127.0.0.1:7860就可以访问SD WebUI了。
如果这还是太麻烦的话,国内也有共产主义战士直接写了个SD-WebUI的GUI启动器,将整个SD的模型管理、核心组件、WebUI、Python环境、Git组件给打成了一个大包,用起来那就极为方便且友好了,作者直接在B站发布了GUI启动器的下载地址:
【AI绘画】绘世启动器正式发布!一键启动/修复/更新/模型下载管理全支持!_哔哩哔哩_bilibili
由于我自己的电脑上已经跑了Python 3.11,又懒得再用Anaconda搭多个Python环境,干脆也就不手动配置WebUI了,直接用GUI启动器。
启动前的设置
从上面的Bilibili的地址下载的WebUI GUI启动器在本地随意一个目录解压(对头,大佬就是大佬,是在B站的一个视频底下直接更新地址的),然后运行里面的A启动器.exe,就可以了。SD WebUI启动器需要依赖.NET Framework 6.0,如果没有安装的话会提示安装,到微软下载中心下载即可。
首次运行可能会需要更新一堆组件,等待就OK了。
启动完成后,你应该看到了那个大大的“一键启动”并且迫不及待地想要去点了?先别着急,我们还是得简单看看WebUI的高级设置,它们可是会影响到后续的使用体验的。
在“高级选项中”,我们需要关注的重点有这些:
- 生成引擎 正常情况下,在这里应该能看到自己使用的电脑的显卡,如果显示的是
-1: CPU并且下拉菜单里找不到显卡,那就说明要么是电脑没有达到前面所说的最低的硬件要求,要么就是显卡驱动过于老旧。头铁用CPU算也不是不可以,就是慢得要命。 - 显存优化 这个按需启用,主要是照顾一下显存不够大的显卡,可以根据自己的显卡的显存大小来调整。比如我在办公室使用的是显存8GB的NVIDIA Quadro P4000,那么稳妥起见我可以开中等显存优化,但是我在家用的是24GB显存的NVIDIA GeForce RTX3090,就大可以放心大胆地调整成无优化。
- 监听地址与监听端口 这个自己架设过服务器的应该很清楚,可以用于从别的电脑访问运行SD WebUI的电脑,就像网站一样。如果只是本地运行的话监听地址留空,监听端口保持默认即可。
- 界面样式 这个主要影响到WebUI启动后浏览器里看到的那个网页的界面风格。和现在的很多网页一样可以选择亮色模式和暗色模式,也可以设置为跟随系统,这样它会根据操作系统的颜色设置来自动调整。
- Xattn优化方案 这个同样是为了优化PyTorch的显存占用。因为某些模型算起来,就算是24GB的民用卡皇也会遭不住,所以需要启用优化,以降低显存占用、提升出图速度。目前NVIDIA显卡当中比较流行的是Xformers,也就是WebUI GUI启动器里标了“推荐”的这个,如果是NVIDIA显卡的话,用这个默认的就OK了。这个选项轻易不要动。 另外需要说明一下,NVIDIA为GeForce RTX40系列显卡开发了专门的cuDDN优化方案,但是目前这个启动器包里还没有带上,如果有需要可以自己下载,根据测试反馈GeForce RTX4070Ti+cuDDN的出图速度比GeForce RTX3090还要快得多,就很离谱。
- 开放远程连接 这个选项主要用于切换是否将WebUI开放给网络里的其他主机,这个自己搭过服务器的不用说就明白,比如要是在一个主机名为
hostname的电脑上运行了SD WebUI并且开启了远程连接,那么同一局域网下的其他设备可以在浏览器里通过http://hostname:7860来访问到这台电脑上的SD WebUI,就和在线服务一样。如果有能力的话还可以通过各种手段将主机丢到公网上,实现任意位置,有网就可以访问。 - 启动完毕后自动打开浏览器 很好理解,勾上这个选项,经过漫长的启动过程后,GUI会自动打开浏览器并且打开WebUI的本地地址,如果不勾的话,就自己手动打开浏览器,输入
http://127.0.0.1:7860就可以访问了。 - 向上采样法提高精度 Upcast Sampling是用于提升模型精度的选项,但是需要付出性能的代价,可以不开。
- 半精度模型与VAE 这个主要是指模型训练使用的浮点数类型,有FP64(双精度)、FP32(单精度)、FP16(半精度),写过程序的都知道分别对应不同的比特数来表示一个浮点数。对于用户来说只取决于手里有没有半精度模型,一般来说也是不用打开的。
- 关闭数值溢出检查 数值溢出自然会造成严重的模型出错,所以这个选项不应当关闭。使用半精度模型更不应该关闭。
- Gradio相关的选项 这里有好几个选项是和Gradio相关的。Gradio是一个Web前端。比较有趣的是,Gradio默认是支持公网发布的,勾上“通过Gradio共享”,同时在“管理Gradio账号密码”中输入自己的Gradio账户和密码,就可以自动生成Gradio的公网地址。有兴趣的话也可以稍微了解一下:Gradio: 让机器学习算法秒变小程序 – 知乎 (zhihu.com)。
- Huggingface离线模式 Huggingface前面介绍了,相当于机器学习界的GitHub。默认状态下SD WebUI启动器会连接Huggingface进行模型的状态检查之类的操作,勾上这个之后就会跳过这些,以纯本地模式运行。
- 无模型启动 这个主要是给前端调试用的,正常使用不应该勾上。
- Accelerate多卡训练加速 看自己有没有SLI或者NvLink组的多卡系统。没有的话(多数人应该没有)可以关闭。
- 关闭模型哈希计算 这个主要是用于验证模型的完整性,并且判断模型管理列表里某个模型是否已经下载。一般来说不用关闭。
至于其他没提到的,特别是界面上标红的那些地方,要么是高压线摸不得,要么是一般不用管的。
疑难解答选项卡,一般是在运行出错之后点一下“开始扫描”,会给出错误的原因和修正的方法。
版本管理选项卡,可以在这里管理StableDiffusion WebUI的版本和更新工作。
模型管理,这里可以管理各种模型,可以在列表里直接点下载,启动器自带的Aria2会将模型下载到本地,如果是别的地方下载的模型,也可以点“打开文件夹”放进去,或者点“添加模型”来加入。
扩展管理,主要是WebUI用到的一些扩展工具,如美学风格切换之类的,可以在里面将部分提示词的输入变成GUI选项。这里主要是用于这些扩展的更新。
将这些选项都检查完之后,就可以启动SD WebUI了。
SD WebUI的启动需要耗费相当长的时间,不夸张地说,这应该是我见过的启动最耗时的软件。主要是因为Stable Diffusion和WebUI都需要一大堆Python Package来支撑运行,启动器需要首先校验这些包是否符合要求,不符合的话还需要到pip上去下载,然后模型数据的加载也需要耗费相当长的时间,耐心等待即可。如果勾选了“启动完毕后自动打开浏览器”的选项,那么这个漫长的过程完成的时候,浏览器会自动打开http://127.0.0.1:7860/,并且显示WebUI。
WebUI使用指南
通过WebUI,可以实现与Stable Diffusion的交互。它就是Stable Diffusion的完全体,可以看到,SD WebUI提供的功能是Playground AI这类在线服务不能比的。
SD WebUI的界面还是相当清晰的,可以看到它能够实现的功能包括:
- 文生图 很容易理解,用户来描述自己想要什么,Stable Diffusion将它画出来。
- 图生图 这个主要的功能包括:
- 以图像作为提示之一来重新绘制一张图片。比如输入一辆汽车的图片,再通过添加提示词,这样SD画出来的图更多地会以这张汽车为基础。
- 在图片基础上涂几笔示意,涂上去的几笔可以用于标识希望重新绘制的部分,也可以用于标识大致想要画的东西的形态。
- 后期处理 如前所述,SD的标准绘图尺寸是512×512,但是我们可以通过后期处理来将一张图片放大。这种放大和Photoshop里直接拉像素那种完全不是一回事,而是相当于让AI重新画一张。
- PNG图片信息 Stable Diffusion会将绘制图片的信息以文本形式保存在PNG当中,一般的看图软件是无法看到这些信息的,通过WebUI的PNG图片信息可以将这些信息提取出来。而且,直接保存、分享这些带有图片信息的PNG文件似乎现在是AI画图社区的通例,所以,将社区上的图片拽下来,丢到“PNG图片信息”里查看原作者是怎么写提示词的也是一种很有效的学习方法。
- 模型合并 用于将多个模型合并为一个大模型。
- 训练 这就是在已有模型的基础上进行增补训练,或者直接从零开始训练一个全新的模型,所谓“赛博炼丹”,就是在这里。
- 训练美学风格模型 一般指训练Dreambooth、LoRA或者Hypernetwork模型。
- 图库浏览器 浏览既往生成的图像,可以在里面将图片和对应的prompt等参数直接调往图生图或者文生图的模块当中。
在开始之前
下面我们将实际演练一下,如何使用Stable Diffusion WebUI来绘制一个想象中的世界。
来不及要启动WebUI了?且慢……
在开始之前,我们需要准备所需的模型。如前所述,Stable Diffusion使用的“模型”有很多种,打开启动器的“模型管理”选项卡就可以看到:

- “大模型” 这里没有出现,因为这类模型我们作为用户极少接触到,在多数Stable Diffusion的整合资源或者在线服务当中已经自带了Stable Diffusion 1.4/1.5/2.1,这类就是“大模型”。大模型拥有完整的VAE、U-Net和文本编码器(SD1.x是OpenAI开发的CLIP,SD2.x换成了开源的Open CLIP)。大模型的训练需要投入巨量的素材资源和算力,一般用户“炼丹”也不会去碰大模型,而是在大模型的基础上进行的调整,如Checkpoint、LoRA等相对来说比较“小”的模型。
- Checkpoint 也就是“Stable Diffusion模型”,平时,我们如果在讨论Stable Diffusion的时候,提起“模型”,如果不带任何上下文,默认指的就是Checkpoint模型。 Checkpoint模型的文件是以
.ckpt或者.safetensor为扩展名的二进制文件,其中.ckpt是比较老的类型,现在是以Huggingface大力推广的.safetensor格式占主流。 作为我们用户使用的模型的主力,Checkpoint对美术风格的影响是最大的。每个Checkpoint还有能绘制的图片内容的区别和限制。在启动器当中,我们可以看到很多预置的启动器,可以一键下载,如果找不到自己想要的模型的话,也可以自己下载,然后单击模型管理旁边的“打开文件夹”按钮,将下载到的.ckpt或者.safetensor文件放进去即可。目前知名度比较高的下载模型的网站有两个,第一是Huggingface,第二是CivitAI。可能需要备梯子才能上得去。 - Embedding模型 前面介绍过Embedding,也就是文字输入后生成Token,Token转换为Embedding Vector的时候,使用的就是Embedding模型。
- Hypernetwork模型和LoRA模型 前面也都介绍过,是在U-Net进行噪音预测的时候劫持Cross-Attention机制的权重并对其进行微调最终影响输出图像的风格,不过这种小模型通常只能有限度地影响画面的风格,但是好处是训练的成本远低于Checkpoint。
- VAE模型 用于将像素空间转换为潜在空间的变分自动编码器模型。一般来说Checkpoint模型会自带,但是也可以外挂。
这些“模型”的概念或许很技术、很枯燥,但是作为用户,我们需要了解的是每一种模型会对结果产生什么样的影响。因此,我画了一些图,应该可以说明问题:
Checkpoint模型的影响,显然是最大的。下面是两张图,提示词都是“a basket of apples on a table with green tablecloth”,生成的Seed是1145141919810(要素察觉),分别使用了Anything 4.5和ChilloutMix来生成,效果如下:

Anything是一个偏动漫的模型,训练使用的也都是大量的日本漫画风格的图片,所以出来的图偏漫画风格、低写实风格也很好理解,而ChilloutMix是一个偏重写实、色彩艳丽的模型,通过这一篮子苹果就很能看出其中的区别。
Embedding模型的影响也不小,下面两张图,提示词、Seed和上面完全一样,模型都是ChilloutMix,但是一个未指定Embedding,另一个在提示词中加了一行“yaguru magiku”,即要求Stable Diffusion使用矢车菊Embedding模型,就会发现生成的图差别很大,这可以理解为Stable Diffusion“理解”输入的提示词的方式不一样了。

下面两个展示了不同的Hypernetwork和LoRA模型的效果:


可以看到,不光画面发生了明显的变化,更重要的是它们的风格发生了变化,这种美术风格上的变化往往是Hypernetworks和LoRA模型的应用重点。目前的趋势是LoRA似乎比Hypernetworks更受欢迎,在社区当中能够选择的LoRA模型远比Hypernetworks要更多。除了画面的美术风格,LoRA还可以给其他很多东西施加影响,如特定的物品、人物的脸型、场景等等,都可以通过外挂特定的LoRA来实现。
在模型面板中选择了对应的LoRA之后,会在prompt当中自动生成调用LoRA的语句,如<lora:sasha:1>。这代表调用名为“sasha”的LoRA,且权重为1。注意这里的“权重”。LoRA的“权重”是可以调整的,而且很好理解,权重越高,LoRA的效果越显著,但是具体的效果需要测试,LoRA权重太低可能不会起效果,而权重太高则有可能出现过拟合的现象,导致出图变成一团乱七八糟的东西,和CFG Scale调太高有些类似。

最后是不同的VAE的效果:

可以看到,VAE的影响力是最弱的,但是我们仍然能清楚地看到在色彩风格上的区别。Anime是一个重点输出动漫风格的VAE,因此也就能从画面上体现出这种改动的趋势。但是需要注意,外挂VAE和Checkpoint之间可能会存在浮点精度的兼容性问题。Anime似乎就是一个半精度VAE,转换成的潜在空间自然也就是半精度的,单精度的模型根本处理不了,就会在控制台里报错。
在WebUI中,我们可以方便地切换这些模型。Checkpoint模型可以在左上角的“Stable Diffusion模型”下拉菜单中选取,外挂VAE模型则在右上方,其他模型可以在“生成”按钮下方的附加模型面板中找到。
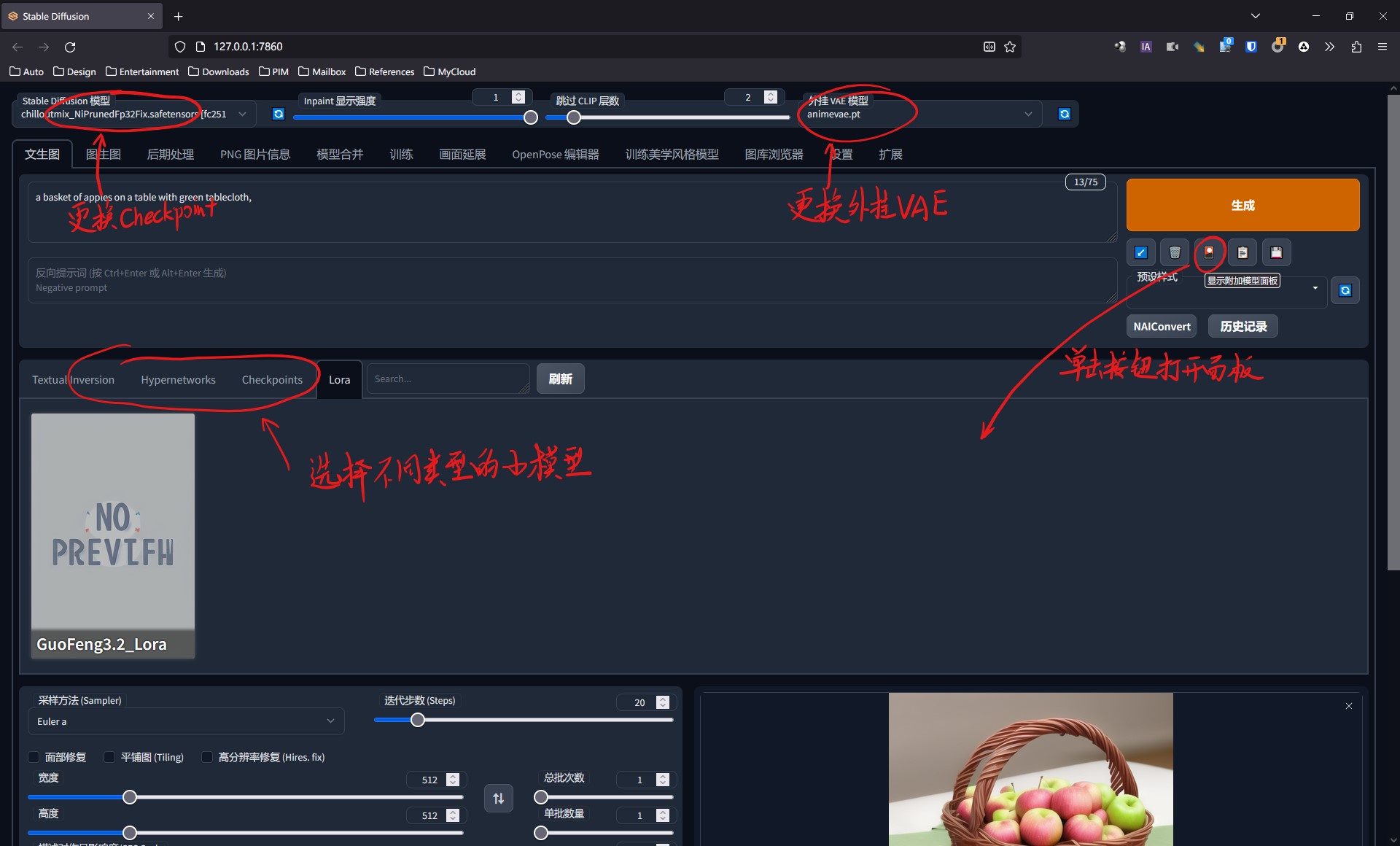
熟悉了这些各种不同的模型之后,我们就可以搭配使用,形成我们想要的效果。
从零开始:文生图与提示词的写法
OK,我们就开始正式使用Stable Diffusion。本文只介绍两个主要的功能:文生图和图生图。
文生图相对比较简单,告诉AI你想画什么东西,就OK了。虽然理想状态下,我们只需要用自然语言(当然,是英语)告诉Stable Diffusion想要画什么,它的CLIP会准确解析,但是实际上,由于Stable Diffusion毕竟还不是GPT或者Claude这样专精于NLP的AI,所以在实际应用中,编写提示词还是有一定套路的,甚至这已经形成了一个细分研究领域,叫提示工程(Prompt Engineering),专门研究人和AI交流时的套路。
Stable Diffusion的提示词分成两套,分别是正向提示词和反向提示词。这个很好理解,分别对应着你想在图里有什么、不想有什么。一般来说,模型作者会在模型的页面上说明模型中有哪些典型的正向提示词和反向提示词,但是这并不意味着只能用模型作者指定的提示词,但是作者指出的这些提示词往往会起到一个“Trigger”的作用,可以触发特定的效果。
如前所述,提示词的书写有一定的套路,这个“套路”不是某种规范,而是一种比较松散的习惯。我个人比较习惯的写法就是三段式:
- 第一段:描述我想要的图像质量和风格。除非是专门要去画一些Low-Fi或者很猎奇的图像的话,一般会写上
best quality、ultra-detailed、masterpiece、finely detail、highres等等。然后是图像风格,如想要类似照片的真实效果,可以加上photorealistic,想要漫画风格,可以加上anime等等。 - 第二段:描述画面的主体和环境。一般用英语的自然语言写出来就OK,可以用逗号来划分不同的描述,希望重点显示的放在前面,不那么重要的放在后面。同时,通过附加的强制性描述来添加细节,如
extremely detailed flower,可以将画面中的花的细节调高。环境方面,可以用cinematic lighting、dynamic lighting、dark ambient等来描述环境光,也可以直接说主体在什么地方来添加环境。 - 第三段:描述视角和其他一些杂七杂八的。一般可以用:
dynamic angle、wide shot、close shot、from above等来描述视角和画面的构图。必要的时候也会添加如black background等描述背景色之类的杂项要求。
这种习惯从某种程度上和我作为一个摄影爱好者有点相似:首先看我掏出什么东西来拍照,掏出个手机代表比较糊弄事,掏出个相机说明我比较认真;然后再安置要拍摄的对象和布置拍摄环境;最后用取景器调整视角。
但是这只是我的个人习惯,每个人都可以根据自己的习惯来形成一套自己编写Prompt的原则。
另外,需要说明的是,在Stable Diffusion的Prompt当中,是可以通过一些特殊的手段为某些Prompt提权的。将一段词用括号()(注意是英文的半角括号!)包括,可以将其权重因子×1.05,可以用多重括号进一步增加权重,如果发现某个Prompt在成图里没有体现出来的话,可以尝试使用括号来为Prompt提权。反过来,用方括号[]可以降低权重(÷1.05)。
且慢!这还没完
在提示词的下面,好像还有一块面板。那是用于调整生成图像的参数的面板。我们不妨一个一个看一下:
首先是采样方式。
如前所述,Stable Diffusion的基本工作原理是从噪音中采样的逆扩散过程。这种采样算法在信号分析这么多年的历史上不说俯拾皆是吧,满坑满谷总是有的。Stable Diffusion就带了很多种采样算法。采样算法的旁边是采样次数。一张图片经过若干采样次数后才可以得到最终输出的图像,但是采样算法和采样次数都会影响到最终成图的效果,我大致做了一下实验(红衣女孩坐在云端撸猫,ChilloutMix Checkpoint),测试了几种采样算法和不同的采样次数,得到的结果如下:

事实上一般的采样算法在默认的20次采样之后就已经能够输出比较准确的结果,我这里设定为30次,可以看到不同的采样算法得到的结果不尽相同,某些算法(如LMS和DPM++的两个),开始还有些猫的痕迹,迭代几次之后猫没了。有些开始非常抽象(DPM2 a),但是最终得到的结果非常不错。这些都要在实际使用当中多测试测试。
然后,是采样器下面的几个选项。
“面部修复”,这个很好理解,在画图的时候,如果人物距离比较远,模型有时候会生成一些面目狰狞的图出来,勾上“面部修复”之后可以一定程度上降低它出错的概率。
“平铺图”,指的是如果一次生成多张图像,要不要自动生成这些图像平铺后的图像。
“高分辨率修复”,和下方的分辨率,这是一个挺重要的参数。默认状况下,Stable Diffusion会生成512×512px的图像,在今天2K遍地走4K不稀罕的时代,这个分辨率属实不算高。但是如果我们将生成的分辨率直接拉高,那会如何?
还记得前面我们介绍的VAE吗?它通过将像素空间转换为潜在空间来节约GPU算力,一个标准的潜在空间对应的像素空间大小就是512×512×3,如果拉大,VAE就有可能会生成多个潜在空间,并各自在其中根据prompt来生成图像,这就导致用户本来想画一个对象,结果输出了两个对象——但是这不绝对,还是需要以实际测试结果为准。
总批次数量和单批次生成的图片数量。这个也很容易理解。由于Stable Diffusion出图带有相当的随机性,因此,普遍需要一次出多张,然后再选出自己觉得满意的进行后续操作的方法。而这里有一个比较重要的参数就是随机数种子(Seed),它会影响到Stable Diffusion画图的起手套路,一般直接设置为-1就可以调用随机数,而如果发现了某个比较满意的图,可以将种族Copy下来粘到这里,做进一步的优化。
CFG Scale,其实汉化页面已经翻译得非常到位了:描述对图像的影响程度。这个默认7一般是不动的。调太低(5以下),出来的东西可能会很掉SAN,调太高了之后,又会出现非常难看的伪影,这两个极端一个是AI太过于天马行空,另一个是AI太束手束脚的结果。但是某些模型在训练的时候过拟合比较严重,此时就需要适当降低CFG Scale或者降低模型本身的权重,以抵消这种影响。
下面的脚本美学优化就很容易理解了,展开之后有很详细的描述,说白了就是用一套GUI来帮用户来写入对应的prompt。这里就不展开说了。
图生图
图生图(img2img)是另一个非常重要的组件。
如前所述,Stable Diffusion的主要反向扩散过程是发生在潜在空间当中,而潜在空间是通过CLIP解析用户输入的文本(prompt)生成的描述向量来形成的。而图生图模块除了文生图的传统过程,还有一个输入源:用户可以指定一张图片作为输入。
用人类能理解的话来描述,就是告诉Stable Diffusion一张图和一些文字,让它参考这张图,同时还需要理解文字,来生成一张图片。
事实证明,Stable Diffusion真的能像人类一样,尝试去在一张图的基础上来再创作——前提:只要不出错。
图生图的基本设定如下:
首先和文生图是一样的,一样需要界定正向与反向提示词。这部分就略过不表。比较重点的是下面的几个部分。
“图生图”是一个功能集,它提供了图生图、涂鸦、局部重绘、涂鸦重绘等功能,最后两个则是用于大批处理的蒙版和批量处理功能,这个用得相对较少。其中最核心的功能还是图生图,其他的都是图生图功能的派生。比如局部重绘,实际上是通过读取笔刷蒙版,在通过图生图生成整张图片后替换蒙版内部的图像内容。所以,核心便是理解图生图的功能。
图生图的控制面板条目与文生图非常相似。如采样方法、迭代步数、宽高、批次数、单批数量等等,不再赘述。比较重要的是这几个:
- 缩放模式
主要的原因是,输入的图片和下面界定的宽度和高度不一定类似。甚至宽高比都不一样,如果出现这种情况,可以再此处设定缩放选项。- 仅调整大小:将输入的图片转换为潜在空间之前,会强制将输入图片拉伸或者压缩到目标缩放比,无视缩放比例。比例裁剪后缩放:保持长宽比缩放填充,将超出画面的区域切掉。缩放后填充空白:保持长宽比缩放适应,多出来的区域填白。潜在空间处理:缩放不在像素空间进行,而是在潜在空间进行,这个一般来说比较少用。
- 重绘幅度(Denoising)
这是一个比较重要的参数,可以在0-1之间调整。而且很直观,重绘幅度越高,对输入画面的改动也就越大。我简单做了一个实验,结果如下:

可以经验性地认为0.2和0.6是两个阈值,低于0.2,输入图像对出图的影响是最大的,甚至在prompt(包括LoRA)里的描述也会被无视掉。0.2-0.6是比较有弹性的数值,不会对画面有很大的改变,但是会体现出prompt的输入,大于等于0.6,那就到了AI相对自由发挥的区间了。比如上面的测试,prompt写的是一条狗和一辆车,但是重绘幅度拉到了0.6之后,狗才开始在画面中出现。在低于0.6的区间内,测试的这一趟没有看到狗。
比较极端的是0和1。0基本上可以认为就是用AI缩放图片,即将图片的像素空间映射为潜在空间然后再反映射回去。而在接近1的数值,图片对成图的限制最小,基本上就是生成一团糊糊然后进行反向扩散,比如最右侧重绘幅度拉到0.95,不光车子早就望之不似高尔夫,车屁股也变成了车头,连颜色都变了。
一般的策略
通过神经网络训练出来的AI——和人类一样,抽风是常态——不对,准确地说还特么不如人类。所以,AI画图很多时候有一个屎里淘金的过程。如果模型足够优质、稳定,也许可以做到每张图都有模有样,但是更多的时候,得生成一大批图,然后在里面找相对满意的挑出来,进行进一步的处理。
所以,一般来说,我个人推荐的方法如下:
首先,将分辨率设定为不超过512×512,因为这是一个潜在空间对应的像素空间的上限,画这么一张小图第一会比较精准,不会用户要求画一个人它给整出来俩;第二速度相当快,以公司五年前配发的NVIDIA Quadro P4000的垃圾性能,也能不那么耽误事。如果是图生图且显卡性能比较强的话,可以将分辨率适当宽限,如1200×800(或者对应的竖版),3:2的分辨率是很多Checkpoint模型训练时的长宽比,图生图在有图片作为输入的前提下,较少出现潜在空间里的Bug,同时足够强大的显卡也不至于在这个分辨率下输出太慢或者直接爆显存。
第二,单批出图数量拉满到8张,是否要多批次出图随意,这样一次就能出一堆图,虽然Stable Diffusion经常性地不靠谱,但是在一堆图当中总能找到那么几张看起来满意的,挑出这张满意的,进行后续的处理。但是需要注意,这些操作都需要相当的显存容量,如果显存不够的话会报错,这时候就需要适当将生成的图片数量减少。
第三,后处理。无论如何,不到512×512的分辨率对今天的显示设备来说还是太低了,因此,我们有必要对它进行后续的后处理。
后处理
由于普遍不太推荐直接绘制尺寸太大的图像,因此,将小尺寸图像放大也就成了刚需。所幸神经网络算法在这方面也是比较擅长的。Stable Diffusion自带了一个用于图像放大的处理单元。
一张图可以选择两级放大算法,关于这些放大算法也都能从论文中找到,我个人比较喜欢用R-ESRGAN 4×+作为第一算法,ESRGAN 4×作为第二算法,强度为0.3-0.5,这对于放大照片来说效果不错,如果是类似漫画那种线条很分明的,那么这里有专门的R-ESRGAN 4×+ Anime来处理,但是照片用这个标了“Anime”的算法会导致模糊和丢细节。
总之这个很容易理解,也就不再展开了。
AI绘图在设计领域的应用
AI头脑风暴
设计师在开始思考自己的方案的时候,往往需要发散自己的思维。方法有很多,可以是头脑风暴,可以是Sketch Battle,而Stable Diffusion的出现可以带来一种新的方式。
虽说AI在训练的时候用的是大量的现有素材,但是和很多人理解的不同,Stable Diffusion在生成图片的时候并不能简单地理解为“用训练的素材重新随机拼凑”。如果引用“Searle的中文屋”的观点,它确实是在某种程度上在进行“创作”。事实上,人类的设计师也很难跳出固有的认知框架去设计一个从未见过的东西。否则克苏鲁就不会顶个章鱼脑袋了——人家作为旧日支配者应该是“不可名状”的,可惜人类能想象到的最猎奇的海生生物就是章鱼。
如果说设计师超出普通人的地方,那就是更大的认知范围和刻意为之的联想训练,比如看到一个很有设计感的建筑,普通人可能就是“Wa”一下,但是设计师会思考这个建筑的设计思路是什么,它可以激发起受众什么样的情绪。
——等!一下!
这是不是很像在训练模型的时候增加素材数量、打Tag的过程?如果说普通人是一个小规模的Checkpoint的话,那设计师就是一个数据规模更庞大的Checkpoint,如果用同样的方式去训练Stable Diffusion的话,理论上是能够训练出这种“通感”和“联想”的——比如将一个建筑的曲线给移植到一辆车上去。
所以,Stable Diffusion的生成是有它自己的“思考”在里面的。由于计算机系统出图的速度远远快过一个设计师在PS里忙活半天的速度,使用Stable Diffusion来协助进行头脑风暴,自然也就不是不可能了。
目前,已经出现了一些针对产品设计的模型,我个人使用的有这几个:
- ProductDesign,一个产品设计的Checkpoint模型。
- AndreaBruno,如其名,以汽车设计师Andrea Bruno(现任Maserati外饰主设计师)的草图训练出来的LoRA。
- SydMead Style,如其名,以著名的科幻设计师、艺术家Syd Mead的风格训练出来的LoRA。作为黄金时代科幻视觉风格的奠基人之一,他的视觉风格比较偏老派,但是非常经典。
- Sasha,以汽车设计师Sasha Selipanov(曾任Lamborghini外饰设计师、Bugatti外饰主设计师、Koenigsegg设计总监,现任Genesis设计总监)的风格训练的LoRA。以铅笔草绘为主,而且众所周知的风格比较狂野。
- Glassball,以Hyundai/Kia的厂稿训练出来的LoRA,也比较接近大多数主机厂的厂稿风格。
下面是使用ProductDesign Checkpoint + Glassball LoRA跑出来的一些图,设想了一下ID.3为基础设计一个小钢炮是什么样子:

可以看到,SD基本上搞出来的东西就是ID.3的车壳加上了一些燃油时代的GTI或者R的设计元素,但是在某些细节上它倒也整出了一些新东西,这些新东西无疑可以启发设计师。虽然新东西出现的概率不一定高,但是生成图片的速度实在是太快了,一个小时跑下来能轻松跑出上百张图片,这样的效率比设计师自己在网上扒意向图要快得多。
训练属于自己的模型
但是,无论如何,拥有一个属于自己的模型还是非常重要的。训练一个模型需要的资源比使用模型要高出不少,显卡的要求也更高——比如新出的GeForce RTX 4060,显存够,画图就没问题,但是由于位宽受限,训练的效率就要打问号了。
Checkpoint的训练相对来说比较困难,但是LoRA的训练就简单多了。因为它是在Checkpoint的基础上进行的小规模数据集的训练,而如前所述,LoRA用于特定主题的物体的生成还是有一定的效果的。所以,对于多数用户来说,训练LoRA模型是最为经济的。如果要训练Checkpoint的话,得要相当强大的硬件配置和足够充足的时间才行。
要训练一套LoRA,同样可以使用WebUI来完成。首先是素材的准备。对训练使用的素材的要求很简单:数量可以少,但是质量一定要高。数量一般控制在30-50张左右,要是数量太多的话,可能会引起“过拟合”的现象
所谓的“过拟合”,可以理解为AI过于关注画面的细节,但是忽视了整体风格的把握。与之相反的概念则是“欠拟合”,也就是对风格的控制不到位。这两者都是在训练时需要规避的问题,规避的方法就是使用高质量的素材并且准确控制Tag。
在开工之前,我们首先需要确定:我们要训练什么类型的LoRA?是特定的物品对象?还是某种美术风格?或者是细致到特定的背景环境?需要确定所有的素材都是围绕我们的目的来展开的。
素材收集好之后需要做两件事情:抠图、裁切。这两件事情也都是为了让图像的主题更加突出。需要注意,最终生成的图像单边像素数需要为64的倍数,至于具体是多少看显卡的显存容量。
然后就是使用WebUI的“训练”标签页里的预处理功能,在生成的时候,可以勾上“使用deepbooru生成说明文字”。Deepbooru是一个通过图像反推说明标签的神经网络模型,在训练时让它自动生成Tag会省很多事情。当然,AI干的事情也是比较糙的,我们还需要使用一款名为BooruDatasetTagManager的软件来处理标签。
GitHub – starik222/BooruDatasetTagManager
然后就是将数据移至LoraTraining/lora-script/train/当中(没有的话新建一个),然后在train目录下建立一个概念目录和名为reg的正则化目录,概念文件夹里就放预处理过的Dataset,可以在前面添加N_前缀,N代表想要训练的次数。正则化是另一个方面的事情了,可以先不用管,准备完成之后,打开训练脚本train.ps1,这是一个PowerShell脚本,可以用Visual Studio Code之类的文本编辑器打开。需要设置一下以下参数:
train_data_dir:用于训练的素材路径。reg_data_dir:正则化素材路径。resolution:分辨率,支持飞正方形,但是单边需要是64的倍数。batch_size:一次性入模型的样本数。max_train_epoches:可以理解为训练的循环次数。
然后比较关键的是学习率参数。学习率可以理解为神经网络模型学习素材的速度,学习率越高,效率也就越高,但是相应的可能会丢失一些细节,所以,合理设置学习率会让模型更加稳定、收敛速度更快、效率更高。
总结下来一句话:如果不知道怎么弄,可以不改。
然后是输出参数:
output_name:模型保存名称。save_model_as:模型保存格式。
参数调整完成后,保存脚本,然后用PowerShell运行脚本,最后会在lora-script/output当中生成对应的LoRA模型。
Reference
- 拉普拉斯妖,著名的物理学四神兽之一,最早由法国学者皮埃尔·西蒙·拉普拉斯在1814年提出,拉普拉斯妖知晓全宇宙每一个基本粒子在每一个时刻的精确的运动状态,从而获知宇宙的全部历史并且能够预知宇宙的全部未来,当然后来有个叫海森堡的德国小年轻抡起不确定性原理的大棒把它的狗头敲碎了,于是去了天国。[↩]
