
28
7 月
使用Wiki进行知识管理
- By IanGoo

什么是知识管理
今天是你第一天开车去某汽车公司上班。
下班的时候,刚拐出停车场开上东风大街,就被堵了个瓷实。烦躁。路上花了足足半个小时才走完区区5公里的路程。
第二天、第三天、第四天,依然堵。
到了周五,你被摁住加班,一直加到5点半多,顶着一脑门子官司开车出停车场竟然意外发现开车行云流水,10分钟到家。
回到家,老板一个电话让你周六去加班。加到下午四点半,回家,依然不赌。
第二周,天天加班,下班时间从4点半到5点半不断变化,你发觉下班的时候堵车高峰差不多在5:20的时候就会过去。而且在开车回家的路上,你发现真正导致拥堵的源头是一个非常奇葩的路口——一个十字路口的路非得错开个十多米,这里就堵得那叫一个神奇……而且无解。
于是,你开始考虑怎么才能让自己爽一些……
看着逐渐化开的雪,嗯,考虑解决方案。
- 是时候拾掇一下自行车低碳生活一下了
- 要不攒攒加班时间,每天多上会儿班?
- 绕个远路?因为开的是手动档的车,碰到堵车会莫名烦躁。
- 要不换个自动挡?反正有员工购车是吧……
- ……
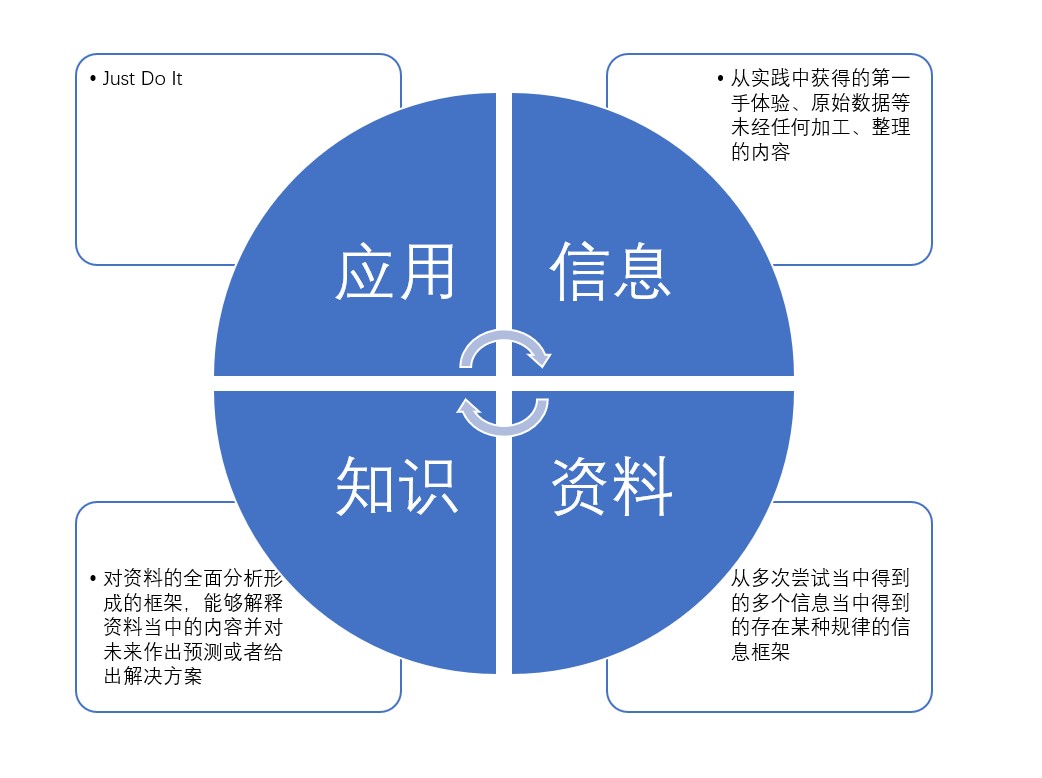
以上,就是知识的提炼和运用的过程。
发现堵车,这是第一步——获得了某个信息。
偶尔加班,这个信息的框架得到了扩展。通过不断的扩展,就可以发现这个星系框架当中的规律,成规律的信息框架,那就形成了资料,或者数据。
通过对资料的深度分析,以及跨学科的整合,你能从起源、过程、结果等多个方面剖析堵车这一现象,这就构成了资料的综合体——知识。知识和资料之间的区别就在于,知识可以导出解决方案。这就是知识的应用。
而从应用当中,你又能获取新的信息。
比如你骑着自行车上班了,结果很不幸地发现路上有一个巨高的立交桥,WTF?
比如你决定开车绕道走,却发现堵车的路口有很多。WTF?
通过对这些信息的探索、整合,又可以形成新的资料和知识,然后指导下一轮的应用。
恭喜你,这就是知识的循环。
知识管理是一个非常庞大的议题。个人的知识管理(Personal Knowledge Management,PKM)是一套,组织的知识管理又是另一套。如何实现信息→资料→知识的转化,如何实现隐性知识到显性知识的转化,还有知识层次之上的能力层次乃至价值观层次,这里的内容多得很。我们今天只聚焦一个东西——如何保存知识。如标题所说,我的建议是使用Wiki的模式。
Wiki思维
大脑是用来思考的,不是用来记忆的
好像好多都在这么说
哦当然,我第一次看到这句话还是Wiz的广告词。。。
而且这也是现在的主流认识。在20年前,媒体上不乏各种“中小学生超强记忆法”之类的广告(实际上现在也还有),能把圆周率背到小数点后1万位的被认为是“神童”。
可现在,只要有个能上网的手机加有信号,你要小数点后多少位?我给你查,100万位以内都行。记这玩意儿有啥用?我们需要知道的是 、
、 这样的东西。当然,最好还要知道这些公式是怎么推导出来的。
这样的东西。当然,最好还要知道这些公式是怎么推导出来的。
论博闻强记,人多数方面领先于电脑,但是在记录信息的精确性、可靠性方面并不及电脑。所以,让电脑成为人的记忆的一个有效的补充,这是极好的。那么问题来了——怎么在电脑里存这类“知识性记忆”呢?
这就是“知识库”(Knowledgebase)的概念。知识库是对个人成体系的知识的一个很好的总结。一个“知识库”应当具备以下特性:
- 能够成体系存放个人的知识
- 能够兼容多种媒体——文字、图片、音频、视频等
- 能够迅速检索其中的内容
- 能够刺激用户去发掘未知,具备扩展性
普通人的做法是在某个磁盘里建立一个文件夹(目录),然后将自己的想法写成Word文档放进去。
嗯。这是一个非常朴素的做法。Word的功能无比强大,可以写出非常漂亮、图文并茂、易读性很强的文档。
但是别忘了知识库有一个非常重要的特性——需要的时候,能够迅速找到东西。
比如,我在知识库里放了怎么根据轮胎规格算轮胎外径的算法。某天突然要用,于是我习惯性地打开了我的知识库想要寻找一下,怎么找?
面对一堆Word文档怎么找?
于是普通人的做法2:分门别类。我在根目录下面建立了一个子目录汽车,然后将Word放到“汽车”里面不完事了?
那请告诉我——“赛车运动”这种东西,是放到“汽车”里面还是放到“体育”里面?
嗯……
而且东西多了之后,可能“汽车”这个目录里会有好几百个Word文档,怎么找?眼睛花没花?
嗯嗯……应该可以so……(嘘……别说,下面我会提到)。
于是,我们有了笔记软件。这类软件现在其实普及程度非常高,包括:
- EverNote/印象笔记
- OneNote
- SimpleNote
- 为知笔记
- 有道云笔记
- 麦库笔记
- …………
选择真的是非常多。而且其中有一些还真的不是不能用来作知识管理。比如为知笔记,在当初还叫“网文快捕”的时候,就有一些PKM的影子了。
除了按照树状结构分门别类地放置内容,也可以为同一个内容添加不同的“标签”(Tag)。
其实我一直认为Tag才是更加科学的文件组织方式。不过目录树存在的时间实在是太长了,命硬得不行,从早期的FAT到NTFS乃至“开放”的EXT文件系统都已经深深打上了树状目录的烙印。一时半会儿是改不掉了。
此外,就是这些笔记软件都提供了颇为强大的搜索功能,只需要输入你想要了解的东西,比如还是轮胎规格和外径的换算方法,我只需要在搜索框内输入“轮胎 外径”,就可以很快地找到我想要的内容。
嗯?刚刚我想说“搜索”来着?
是啊,可是Windows自带的文件搜索只能搜索文件名你忘了?要实现搜索文件内容,还得另找解决方案,如果有这能耐和见识应该早就滚去用笔记软件了吧。
不过话说回来,笔记软件是不是一个合格的“知识管理”系统呢?
我认为,并不是。
笔记软件当中我用过最适合当PKM的产品——为知笔记。但是它有一个功能用起来简直是太蛋疼了——笔记之间的互相链接。
为什么这样的内部链接很重要?并不难理解。假设我在整理关于第一手研究当中数据获取的方法:
常用的数据获取的方式包括观察、访谈、问卷、焦点小组访谈、卡片排序……
一个合格的知识管理者肯定会对这里的“观察”、“访谈”这样的细节感到好奇——更不用说整理的内容是自己本专业的东西的话,敏感度一定更高。那这时候,就会想着去了解什么是“观察”,什么是“访谈”。
这里,就是内部链接发挥作用的时候。如果我在“观察”上点一下,就可以进入另一篇关于观察法的详细描述的页面,是不是很好呢?
Bingo!
这就是Wiki的思路。
但是,笔记软件插入链接怕是很蛋疼。以为知笔记为例,需要先建立一个“观察法”的笔记,然后右键→高级→复制笔记地址,然后再在链接文字上插入超链接。
相比之下,一个成熟的Wiki系统用起来就很爽了。我只需要这么写就行:
常用的数据获取方式包括[[观察]]、[[访谈]]、[[问卷]]、[[焦点小组访谈]]、[[卡片排序]]……
这里用了很多双方括号,这就是多数Wiki插入超链接的语法。如果我的Wiki系统里已经有了“观察”这个节点,那么保存后点一下就能进去,如果没有,就会显示成一个指向无效地址的空链接,但是空链接也是有用的,点进去之后就可以创建这个节点。
这就将很多相关的知识点互相链接了起来,形成了一个有机的知识网络,而且更妙的是,由于允许空链接的存在,这个知识网络还是可以自行生长的!对于我感兴趣的内容,我可以用一个空链接先占着,整理好了之后就从这个空链接出发,新建一个节点。这就是Wiki最妙的地方。
整理起来,Wiki的知识思路包括:
- 以搜索为入口
- 知识节点之间互相链接
- 利用空链接拓展知识网络的外延
对于团队知识管理来说,Wiki还有另一个非常重要的特点:支持多人编辑。团队的力量一定比一个人的力量更加强大。
另外,在Wiki系统当中,虽然有类似于“文件夹”的“命名空间”的概念,但是我个人而言并不建议专业性比较强的Wiki使用过于复杂的命名空间,而是提倡将所有的东西都统一丢在根命名空间:当中,然后靠搜索来寻找自己想要的东西。分门别类地找东西,这种做法太落后了。计算机既然擅长找东西,那就让它去找。让擅长的人(物)做擅长的事情。
Wiki系统简介
Wiki系统,是一种非常有效的知识管理系统。它的应用规模可大可小,可一人使用可团队使用,灵活性极高。
且慢,什么是Wiki系统?
迷茫群众
这还不简单?上维基百科或者百度百科看看,这两个其实都属于Wiki系统。虽然后者并不能算100%的Wiki系统(内容编辑有限制)。
Wiki的理念来自Ward Cunningham。

1980年代晚期,Apple II系列电脑还很流行,而World Wide Web还不存在。那时候,Apple IIGS上有一个叫做HyperCard的功能,HyperCard被认为是WWW之前最成功的超媒体系统。在HyperCard当中,信息存储在一系列“卡片”当中。但是从卡片到卡片的超链接创建起来非常费劲,于是Ward Cunningham利用HyperCard的搜索功能在里面添加了卡片到卡片之间的快速超链接功能。这个超链接若是指向一个有效地址就会跳转,若没有,电脑就会响一声,长按这个按钮就会创建一个新的卡片。Cunningham向朋友展示了这个程序,如果有人指出卡片中的内容不太对,他们就可以当场利用HyperCard进行修改,并且补正卡片的链接。
后来Cunningham又增加了多用户写作功能,Wiki基本就这么成型了。
2002年,一个非常重要的Wiki引擎出现了——MediaWiki。这也是Wikipedia背后的引擎。MediaWiki基于HTTP+PHP+MySQL。彼时Wikipedia在2001年刚刚推出,在MediaWiki出现之后就立即切换到了这个引擎。
MediaWiki遵从GPL协议发布,完全开源。不过,MediaWiki和常年使用桌面软件的人认识的“软件”不太一样。下载下来之后,你会看到一堆文件,唯独找不到exe文件。
重复一下:MediaWiki基于HTTP+PHP+MySQL,想要用的话,得有一台这样的服务器才行。
多数Wiki诞生于互联网的黎明时代,加上Wiki原则当中有很重要的一条——多用户协同编辑,因此,多数Wiki都采用了B/S软件的模式,即部署在特定环境的服务器上,多个用户可以用浏览器访问该服务器,来使用Wiki软件。
慌了慌了……服务器好贵的!
慌啥……第一,服务器并不贵,任何一个可以连接互联网的电脑都可以当服务器,哪怕是一台配置已经非常过时的笔记本电脑,甚至一台过时的手机或者平板都可以。服务器并不是某种贵的要死的特定的电脑,只要一台标准的计算机,能够上网,能够通过特定的协议在网络上访问它,那它就是一台服务器。
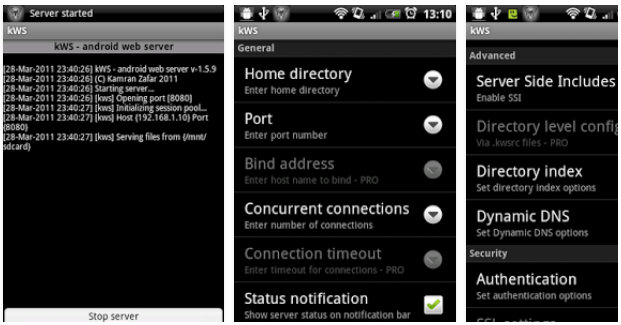
我们说的HTTP,是访问协议。就是超文本传输协议(HyperText Transfer Protocol),我们平时上网都靠他,访问MediaWiki也是一样的,需要让浏览器能够获取服务器里的数据,依靠的就是这个协议。
PHP和MySQL,前者是动态服务器,后者是数据库。稍微熟悉电脑都知道浏览器可以读取的是HTML,但是常规的HTML是静态的,无法实现很多软件功能,于是有了动态服务器,DHTML凉透了之后,目前如日中天的是两个,来自微软的ASP.NET,很强大但是要收钱,以及开元免费的PHP。PHP凭借着开源免费的特性吸引了众多开发者,我们所熟悉的很多Web软件,如今天提到的MediaWiki和下面很多Wiki,以及做网站/Blog的WordPress、Drupal、Joomla!等等,都是利用PHP写成的。PHP会解析用户的请求,然后动态生成页面传输给访问者的浏览器。MySQL就是数据存储的地方,它是一个数据库,可以将PHP+MySQL理解为一个非常强大的图书管理员+图书馆。用户想要什么东西,图书管理员会飞速从图书馆里找到用户想要的东西,然后拼成一个非常漂亮的Poster交给用户。至于用户怎么向管理员提要求、管理员怎么把Poster交给用户,这一套规范就是HTTP。
除了用废旧设备搭建一个真正的服务器,单机其实也可以用,就是所谓的本地服务器,在网络上这有专门的一个地址:localhost或者127.0.0.1,这被称为“Loopback”,访问这个地址,其实就是在访问本机。如果本机正在运行相应的服务器,那么就可以在本机上使用本来为Web设计的服务。比如我在本机上用FileZilla搭建了一个FTP服务器,那么通过ftp://localhost就可以访问本机服务器权限允许的文件。如果在本机搭建了一个HTTP服务器,那么自然也就可以用浏览器上本机的网页。
不管是本机还是网络访问,如果使用的是Windows,最简单的就是用XAMPP了。XAMPP是一套Apache(HTTP服务器)+PHP+MySQL的集成。以下是简单步骤:
- 下载XAMPP并安装。若下载的是Portable版本,下载后运行一下
setup_xampp.bat初始化一下即可。 - 将MediaWiki解压到
xampp\htdocs目录当中的一个新建子目录当中,比如xampp\htdocs\wiki。 - 运行XAMPP,访问
localhost/wiki。首次安装即可,按照提示流程一步步走。
更强大的是,如果是可互相访问的两台电脑,比如处在同一个LAN当中的电脑,若在其中一台当中安装XAMPP,就可以在别的联网设备当中通过这台电脑的IP地址来访问,就和上网一样。
其实本质上说,我们平时上网和这个是完全一样的原理。只不过互联网访问的是一台远方的电脑,并且通过了DNS的解析不用背IP地址而已。
MediaWiki和WordPress、Drupal、Joomla!这样的CMS一样,是将内容保存在MySQL数据库当中,安装的时候MediaWiki会索要MySQL服务器的地址、用户名和密码,这可以在phpMyAdmin当中设置。
——这正是很多刚刚接触CMS的人晕倒的地方。
有没有不用MySQL数据库的Wiki引擎?
当然有,DokuWiki就是。我的Wiki和在办公室里构建的DesignWiki,都是在DokuWiki的基础上搭建的。
DokuWiki与MediaWiki相比,最大的优势就在于——它的数据是以txt保存在服务器的文件系统当中的。这么做最大的好处就是通用性——只要你的电脑不是70年代以前的那种,都可以处理txt文件。
由于不涉及MySQL,自然也就不需要在安装的时候设置数据库,速度非常快。但是DokuWiki仍然需要PHP来处理页面,需要用http来访问页面。相对来说简化很多,除了XAMPP这种庞然大物,还可以自己用Apache或者nginx搭建HTTP服务器,PHP也可以自己配置。当然,如果不想太复杂的话(毕竟开源软件配置起来没有控制面板那么直观),可以使用DokuWiki提供的神器。在下载的时候,DokuWiki可以选择自带服务器的包,自带一个Apache和PHP,只需要点一下一个bat文件,就可以自动启动服务器,并且打开本机的localhost:8800,然后,就可以和在浏览器上一样访问了。
最后一个推荐,是人民群众喜闻乐见的本地软件——是的,没有任何服务器,没有PHP,没有MySQL,没有Apache,没有NGINX。就是一个简简单单的本地软件——Zim Desktop Wiki。
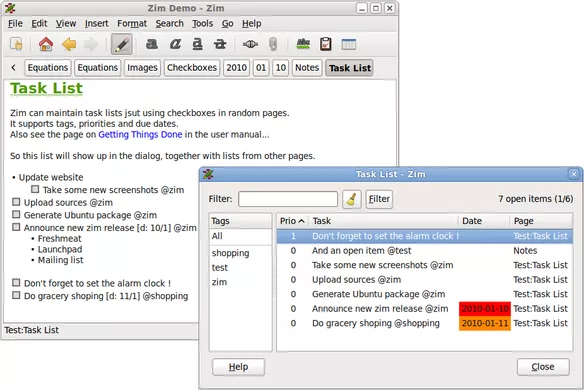
其实Zim只是将原本由PHP解析的东西转移到了本地代码,很简单。它的数据结构依然是一堆DokuWiki语法保存的txt文件。
Zim另外一个好处,是它完全开源、跨平台。除了Windows之外,还可以在各种Linux发行版上使用。它还支持众多插件,可以实现很多有意思的功能,如To-Do、Taglist等。
其实,最好还是……
对头,MediaWiki也好,DokuWiki也好,都需要网络访问。而网络访问都会涉及到一个问题:怎么才能找到运行你的Wiki引擎的那台电脑(服务器)?
当两台电脑都在同一个局域网当中的时候还好办,可以了解服务器的IP地址。但是若是进入了Internet的汪洋大海呢?
这就很头疼了。几个解决方案——VLAN、DDNS,以及自购主机+域名。
我选择的是最后一种,花销比较大,但是很方便,只要有一台联网的电脑(或者手机/平板),就可以使用,非常方便。而且虚拟主机可以做的事情很多,除了放Wiki还可以做一个个人网站——就像这个网站一样。
由于DokuWiki、MediaWiki的知名度很高,因此不少自安装脚本如Softaculous、BitNami、Softron等,都有收录。一键安装,也能省很多事情。
当然,随着NAS的普及,买一台群晖,也能做很多很多事情,包括用WebStation架设一个Wiki网站。Web Station支持PHP、Apache/Nginx和MariaDB,已经构成了一个非常完整的HTTP+MySQL+PHP的环境,而且容量很大。最关键的是可以使用DDNS/QuickConnect在外部连接。
这也是我目前使用的方案。