
22
1 月
如何理解“数据库”?
- By IanGoo

“数据库”这个概念,如果对计算机有一定了解的话肯定会听说过。字如其名,“数据库”肯定就是用来存储数据用的。可我们的U盘、硬盘不也能存储数据吗?数据库又有什么特殊的呢?
OK,现在假设,你是一家集团公司的HR,你上司让你管理分公司三个大佬的人事信息,他一边说你一边记,笔记本(纸张意义上的)上留下了这三位大佬的信息:
嬴政
44岁,祖籍陕西咸阳,出生于河北邯郸,毕业于西北工业大学,专业为土木工程,现担任大秦分公司规划总监,工龄19年,工号0211。
李世民
52岁,祖籍甘肃临洮,在山西太原出生,毕业于太原理工动力系统工程专业,现担任大唐分公司人力资源总监,工龄24年,工号0626。
赵匡胤
50岁,祖籍河北涿州,出生于河南洛阳,毕业于郑州大学自由搏击专业,现任大宋分公司安保总监,工龄26年,工号0960。
这是一种很常见的数据记录方式,我们平时在生活中随手写在笔记本上的Memo就是这种类型,而我们如果将其以文字系统输入不管是记事本还是Word然后存放在一台电脑上,本质上与这种记录方式没有区别——这是一种以自然语言形式记录的数据。
很明显,以计算机的视角来看,这种记录方式显然是很不规范的,让计算机处理这样的数据,就会非常费劲。所以,我们可以看看这三个皇……不是,这三个员工,有哪些“特性”:
- 基本信息
- 教育信息
- 任职情况
Bingo!这种思路,就是现代数据库的一个基本特征——结构化。我们保存在同一个数据库当中的东西,总归是有一定的相似性的。比如库房数据库里肯定放着的都是库房里保存的备品备件,人事数据库里保存的肯定都是员工的信息等等,我们日常去检索这些信息,依赖的是这些信息的某种“特征”,比如在员工的数据里找具体的哪个人,或者工作年限已经达到多少多少年的员工。这样,就相当于对信息的表述作出了一个规范化。在这样的案例中,这三个员工的信息,在数据库中就对应着三条“记录”,而用来描述这些记录的“特征”,则被称为“字段”。
如果我们用基本信息、教育信息、任职情况这三个字段去重写上面这三位员工的档案,就会变成这样:
嬴政
基本信息:
工号0221,44岁,祖籍陕西咸阳,出生于河北邯郸。
教育信息:
毕业于西北工业大学土木工程专业。
任职情况:
工龄19年,现任大秦分公司规划总监。
李世民
基本信息:
工号0626,52岁,祖籍甘肃临洮,出生于山西太原。
教育信息:
毕业于太原理工大学动力系统工程专业。
任职情况:
工龄24年,现任大唐分公司人力资源总监。
赵匡胤
基本信息:
工号0960,50岁,祖籍河北涿州,出生于河南洛阳。
教育信息:
毕业于郑州大学自由搏击专业。
任职情况:
工龄26年,现任大宋分公司安保总监。
Emm,变清晰了不少。但是这么分,合适吗?——每个类型的“特性”其实都很粗,这也不符合现代数据库的另一个重要特性:原子化。
数据库的本质上是为了方便程序对信息的检索,电脑尤其擅长于在一大堆数据中找到符合条件的数据,但是前提是你得喂给他足够规范化的数据,否则就会给程序的编写带来很大的麻烦。我们日常生活中使用的软件,一部分是程序,另一部分是数据,程序需要从数据库中获取特定的数据用于处理,不够原子化的数据表述就会非常麻烦。
比如,“基本信息”字段当中,写着“工号XXXX,XX岁,祖籍XXXX,出生地XXXX”这么一大串文字,但是程序只想要知道员工的年龄,然后求一下公司在册员工的平均年龄,这时候就得写好长一段字符串处理代码将员工“XX岁”里的“XX”提取出来,转换成整型数据再求平均数,极其麻烦。而如果一早就将这些数据打碎,直接以整型数据将员工年龄存储在“年龄”字段当中,程序就可以直接很方便地将这个字段的所有数据起出来求平均,非常简单快捷。
因此,对于这三位员工记录的字段应当这么设定:
- 工号
- 年龄
- 祖籍
- 出生地
- 毕业院校
- 专业
- 任职分公司
- 职位
- 工龄
数据库对原子化的要求非常高,这里的“年龄”和“工龄”,全世界都默认按“年”来计算还不算个问题,但是在某些场合下,单位都是要被拆分出来的。比如库存统计数据,“3盒”、“6个”这样的记录数据是不被允许的,因为这样的数据实际上是“数量”+“单位”的表述方式,这是两个字段的缝合,应当被拆开。记录为“3”“盒”、“6”“个”。
字段存储的数据类型也不一样,如“年龄”(准确的说应当是“年龄/岁”),存储的就应当是一个整数,而祖籍、出生地这些,存储的都是字符串。因此字段的完整设置如下:
| 字段 | 数据类型 |
|---|---|
| 工号 | 文本(text) |
| 年龄/岁 | 整型(integer) |
| 祖籍 | 文本(text) |
| 出生地 | 文本(text) |
| 毕业院校 | 文本(text) |
| 专业 | 文本(text) |
| 任职分公司 | 文本(text) |
| 职业 | 文本(text) |
| 工龄/年 | 整型(integer) |
这里还需要注意一个概念:主关键字(Primary Key),或者称为“主键”。主键的作用是唯一地标识某个记录。主键与记录应当保持严格的一一对应,并且不应当出现空主键,主键也不应当重复。对于本例来说,主键是什么?
在日常生活中的类比就是找一个人,我们找人一般是通过姓名来找,但是公司大了之后,难免重名重姓,毕竟现在又不是秦朝唐朝宋朝那样的帝制时代,避讳什么不存在的。计算机要找李世民,结果在姓名一栏里翻了一下找出来十几个李世民,哪个是哪个?这种情况下,用不会重复的东西——比如工号来作为主键就科学多了。当然,主键也可以由不止一个字段构成,比如员工(分公司,职业),多字段主键一样要保证和记录的一一对应,如果同一个分公司干同一个职业的还是有两个李世民,那也是错误的主键设置。
通过记录和字段,我们就构成了一个数据表:
| 工号(Key) | 姓名 | 年龄 | 祖籍 | 出生地 | 毕业院校 | 专业 | 任职分公司 | 职业 | 工龄 |
|---|---|---|---|---|---|---|---|---|---|
| 0221 | 嬴政 | 44 | 陕西咸阳 | 河北邯郸 | 西北工业大学 | 土木工程 | 大秦分公司 | 规划总监 | 19 |
| 0626 | 李世民 | 52 | 甘肃临洮 | 山西太原 | 太原理工大学 | 动力系统工程 | 大唐分公司 | 人力资源总监 | 24 |
| 0960 | 赵匡胤 | 50 | 河北涿州 | 河南洛阳 | 郑州大学 | 自由搏击 | 大宋分公司 | 安保总监 | 26 |
OK,这下,这三位员工的信息就构成了一张“数据表”。
当然我们不妨思考一下,上面的设置真的做到最原子化了吗?
其实也不一定。比如姓和名是可以继续分开来的。这样如果想要在集团里开一个“老赵家宗族大联欢”什么的,数据库查询更加方便。不过如果没有这样的业务需求,这么设置也大致没有问题。
顺便说一下,其实还是分开比较合理。万一集团公司招了个老外叫Napoléon Bonaparte,人家的姓和名的设置和中国的习惯不同,分开设计字段的应用灵活性就更高一些。
“数据表”就是一系列“记录”构成的二维表格,纵轴是“记录”,横轴是“字段”,而盛放这些数据表的“文件柜”,就是数据库。主流的数据库软件都是采用的这样的两层架构管理数据的,即数据库-数据表的结构。
不过再看看上面这张表,或许有人会陷入沉思……Emm,某个绿汪汪的、微软出的软件,好像……就是干这个嘛……
办公室民工——尤其是财务民工看着就反胃的软件,Excel。
一点都没有错,Excel也可以用于数据的存储,但是和正经的数据库——哪怕和同样在Office套件里的邻居Access相比,Excel还是有一些地方让它无法成为真正意义上的“数据库”:
其一是结构化,某种程度上说,Excel允许非结构化的数据存储。“合并单元格”或者某个单元格留空这种很不规范的事情在Excel里比比皆是,而且大家都司空见惯。
其二是原子化,Excel里面可以出现复合数据,我们也经常见到这样的表格。
数据库的两个重要原则在Excel上都可以突破,Excel当然就不能算正经的数据库了。
究其原因,还是因为Excel这个“数据库”对接的“程序”比较牛批——那可是天然智能(人脑),对模糊信息的处理能力强到爆炸,而和传统数据库对接的程序都很传统,都呆呆的,因此需要高度结构化,才能提高数据的处理效率。

上图的数据表在Excel当中经常能看到。这样的数据表,如果用数据库的写法会是什么样子呢?(上图并不是Excel,而是和Excel相似的电子表格软件LibreOffice Calc,正好LibreOffice里面也有和Access对标的数据库软件)

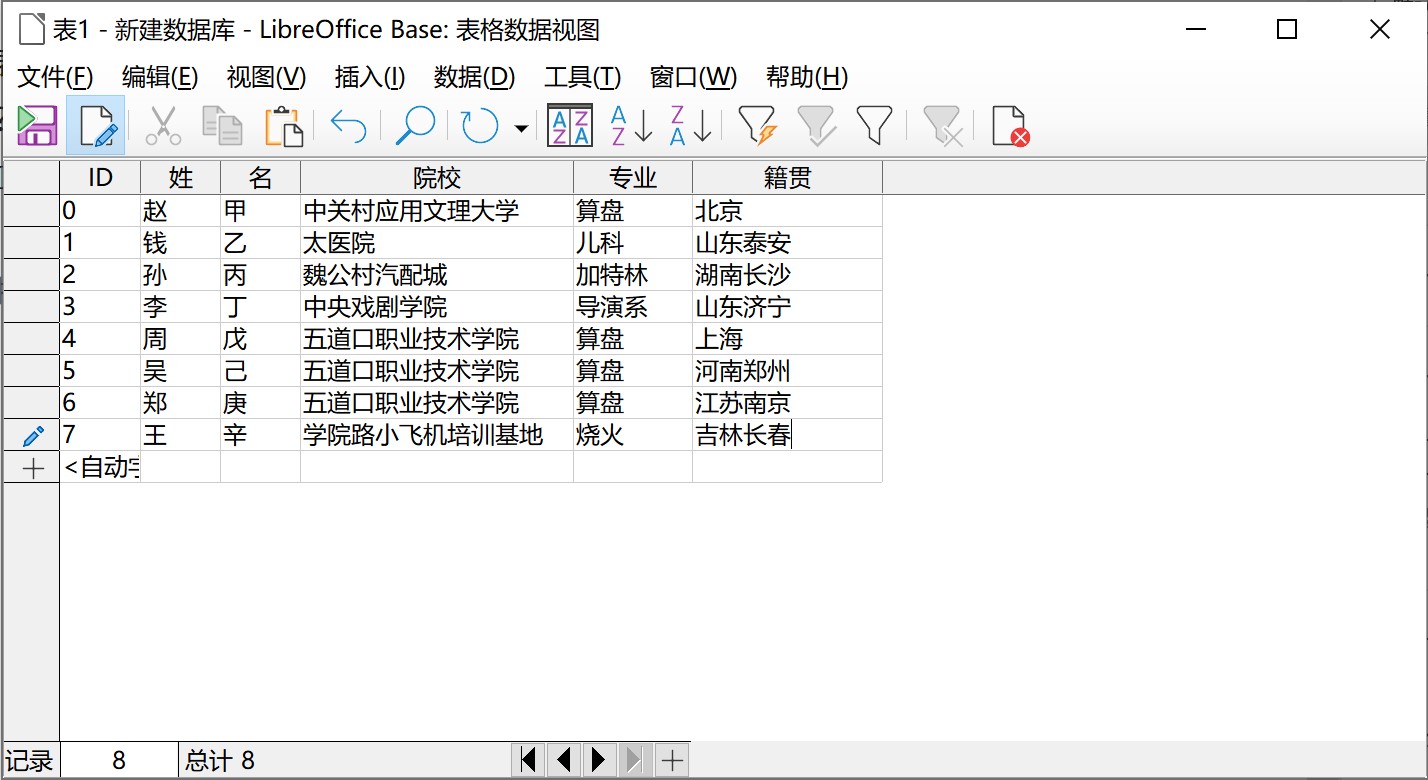
这就是一个比较规范的数据表了。
数据库建立完成后,还需要应用,才能显示出数据库的巨大价值。一个最简单的例子就是查询。以上图的数据库为例,可以建立一个“查询”,比如查找所有算盘系的学生,结果很快就可以出来:
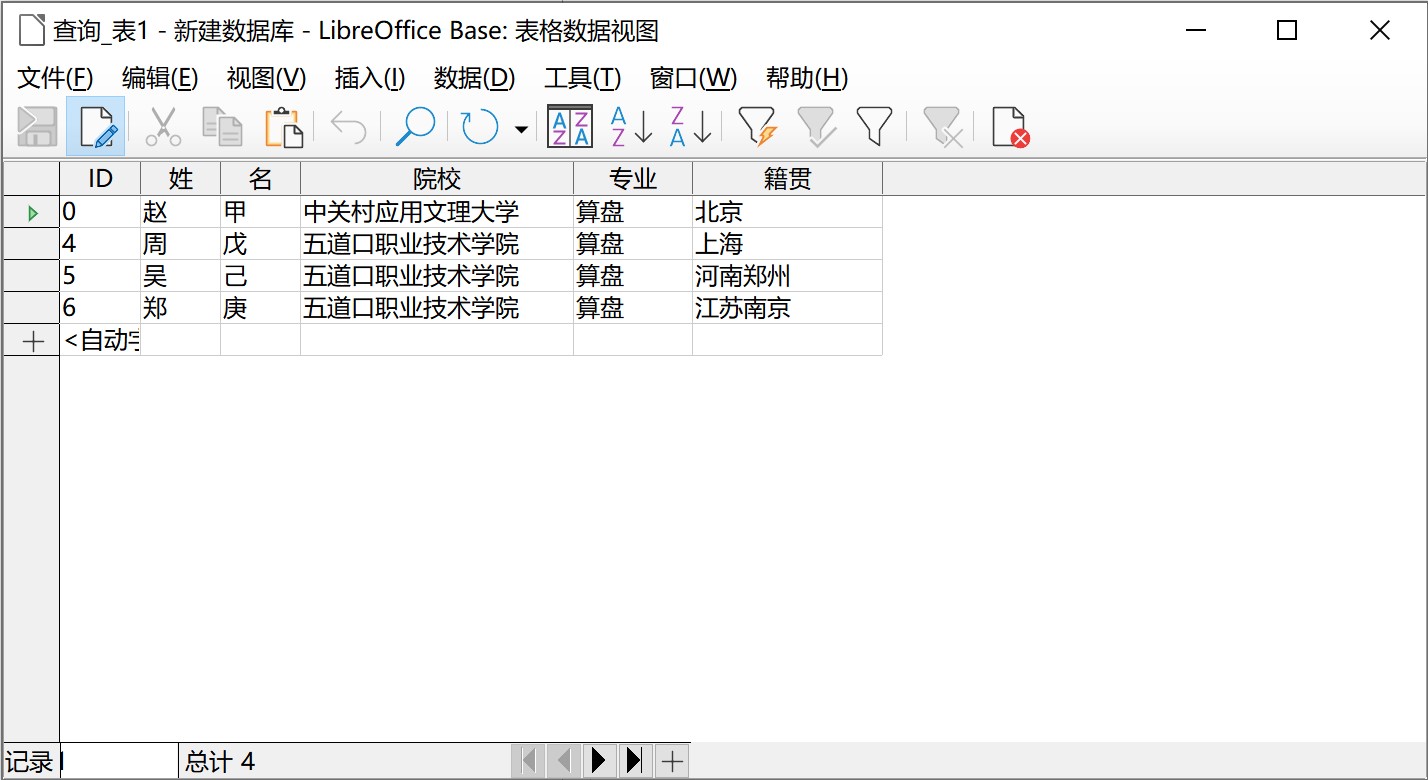
那么,这和Excel的数据筛选有何不同?
答案就是可编程性。数据库由于设计非常严谨,因此对于程序来说非常友好。比如查询语句的设定和保存,假想一下,如果你手头有成千上万持续更新的汽车资料,而你经常需要固定在其中寻找特定的数据(比如A级车的轴距),这样的数据查询功能是可以固化下来的,需要查找这些数据只需要双击一下就可以搞定。
另外,数据表和数据表之间还可以完成关联,这就是现代数据库的另外一个重要的特性——关系性。比如,可以在一个数据表里存储员工的信息,另一个数据表里存储员工的绩效考核结果,两个数据库可以归属不同的团队来维护更新,只要保持两者之间的关系不断即可。
而且Access、LibreOffice Base(还有计算机二级的老朋友、天国的FoxPro),都属于本地运行的单机数据库,而当数据库联网之后,那威力将成倍增长。
因为网络是一张数据的巨网。
事实上,专用数据库的出现恰恰是因为互联网的数据量太过于庞大,使得企业不得不专门拨出算力和存储用于数据的存储和处理。时至今日,数据库已经成了很多在线应用的骨骼,如我们非常常见动态网站,PHP+MySQL+HTTP就是一个使用极为广泛的黄金组合,诸如WordPress、Drupal、TYPO3、MediaWiki这样的CMS都依赖于MySQL数据库。
包括你现在看到的文章,其实就是保存在数据库里的一段数据:
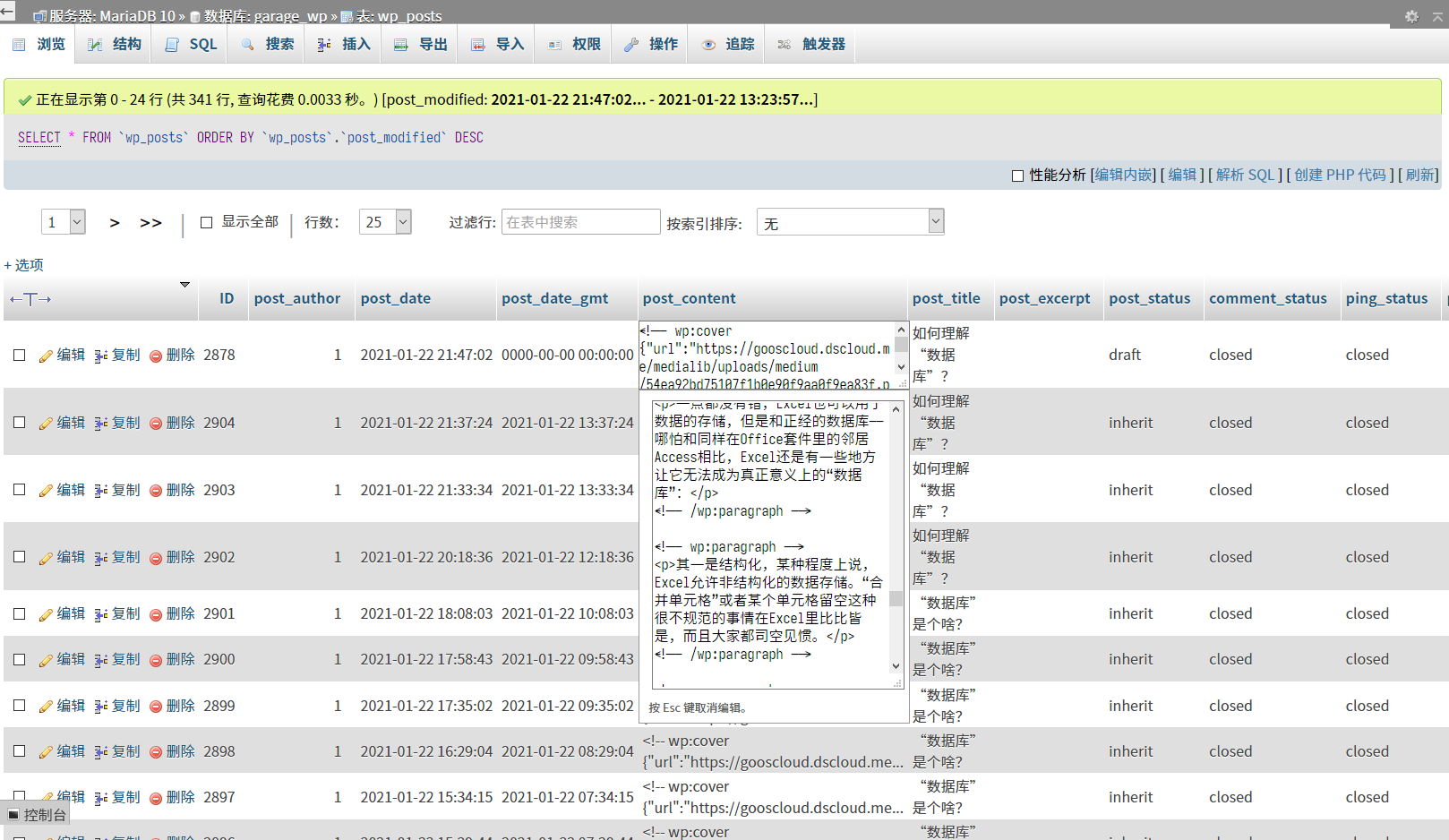
我在WordPress的后台写着这篇文章,PHP将文章的内容通过MariaDB保存进了数据库,在浏览这篇文章的时候,PHP再通过MariaDB从数据库中调取了这篇文章的内容,将其处理成HTML呈现在浏览器上。而在其他的字段,可以看到这篇文章的很多其他属性:什么时候修改的、是否发布、是否开放评论等等,这些都直接关系到一篇文章在网站上的呈现效果。
这仅仅是数据库在现代信息领域当中一个非常常见的应用领域,数据是现代社会的基石之一,数据库自然会扮演极为重要的角色。就算是非IT专业人员,不会操作数据库,也不会SQL,也需要了解一下数据库的基本原则。本文就是一个不怎么专业的人写的、帮助同样不怎么专业的人去了解数据库的工作原理的文章,如果能通过本文了解到数据库的基本原理,那么本文的目的也就达到了。如果想要更深入了解,那就是一个无底深坑了: